Nodejs、GraphQL、MongoDB、Hapi 和 Swagger 构建 API(二)

可重用 API 流行的最大原因是 API 允许使用来自 Web 客户端、移动应用程序、桌面应用程序的数据,实际上是任何客户端。将构建一个基于 Nodejs,由 MongoDB 数据驱动的强大而灵活的 GraphQL API,并支持 Swagger 文档。
项目代码仓库:https://github.com/QuintionTang/powerful-api
系列文章:
创建 Models
在开始创建数据模型之前,先把上面连接数据库的代码稍微整理一下,将其封装到一个文件中,创建文件名 mongoConns.js,代码如下:
const mongoose = require("mongoose");
class MongoConns {
constructor() {
this.getMainDB = this.getMainDB.bind(this);
const mongoUrl = "mongodb://127.0.0.1:27018/powerful";
this.mainDB = mongoose.createConnection(mongoUrl, {
useNewUrlParser: true,
useCreateIndex: true,
useUnifiedTopology: true,
});
this.mainDB
.then((db) => {
console.info("Connected to MongoDB mainDB");
})
.catch((err) => {
console.error("Failed to connect to mainDB", {
params: { err: err.message },
});
});
}
getMainDB() {
return this.mainDB;
}
}
let mongoConns = null;
module.exports = () => {
if (mongoConns) return mongoConns;
else {
mongoConns = new MongoConns();
return mongoConns;
}
};
对于 MongoDB,遵循模型约定,接下来进行数据建模。这是一个相对简单的概念,将能够掌握。基本上,只是为集合声明对应的模式。可以将 MongoDB 的集合视为 SQL 数据库中的表。
在项目根目录下创建文件夹 models,在文件夹 models 中创建数据模型文件 Painting.js,代码如下:
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const mongoConns = require("../mongoConns")();
const PaintingSchema = new Schema({
name: {
type: String,
},
url: {
type: String,
},
techniques: {
type: [String],
},
});
module.exports = mongoConns.getMainDB().model("Painting", PaintingSchema);
- 需要 mongoose 依赖
- 引入数据库连接并初始化 mongoConns
- 通过调用 mongoose 架构构造函数并传入选项来声明
PaintingSchema。注意它是如何强类型化的:例如,定义了name字段可以由一个字符串组成,而techniques由一个字符串数组组成。 - 导出模型并将其命名为
Painting
增加新的路由
理想情况下,希望 URL 端点反映相应的操作。例如 /api/v1/paintings 或者 /api/v1/paintings/{id} 等等。
从 GET 和 POST 路由开始。 GET 获取所有 Painting ,POST 添加新的 Painting。
回到根目录文件 server.js,添加两个新的路由代码:
const API_ENDPOINT = "/api/v1";
const init = async () => {
server.route(
{
method: "GET",
path: "/",
handler: (request, response) => `<h1>This is powerful api.</h1>`,
},
{
method: "GET",
path: `${API_ENDPOINT}/paintings`,
handler: (req, reply) => {
return Painting.find();
},
},
{
method: "POST",
path: `${API_ENDPOINT}/paintings`,
handler: (req, reply) => {
const { name, url, techniques } = req.payload;
const painting = new Painting({
name,
url,
techniques,
});
return painting.save();
},
}
);
await server.start();
console.log(`Server running at:${server.info.uri}`);
};
请注意,将路由修改为对象数组而不是单个对象,还使用了箭头函数。
- 为
/api/v1/paintings路径创建了一个 GET 路由。在处理程序中,mongoose schema 方法 find(),它将返回所有记录,因为这里没有没有传递任何条件来查找。 - 还为
/api/v1/paintings路径创建了一个 POST 路由。这样的API设计将遵循 REST 约定。
在浏览器中输入 http://localhost:3006/api/v1/paintings,将在页面上看到一个空数组。
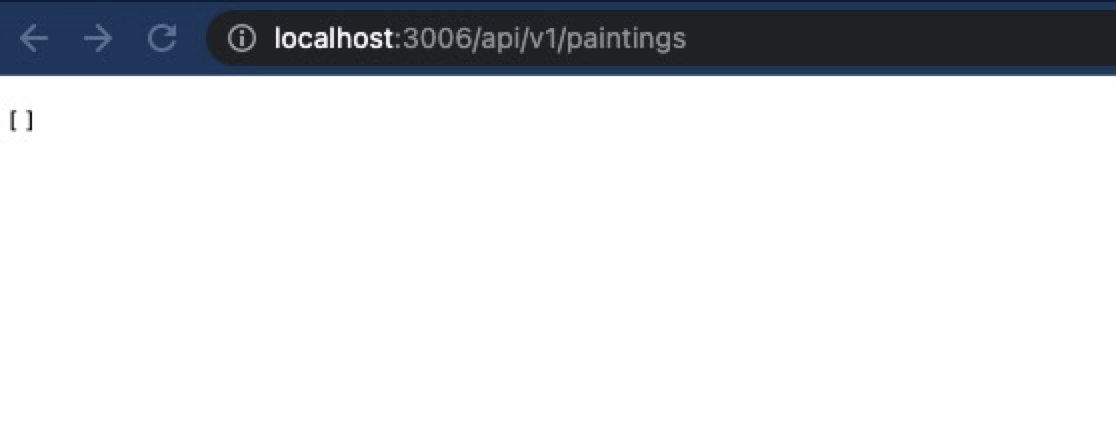
接下来调试 POST 的接口,需要按照工具 Postmain,下载安装好。
打开 Postmain ,创建一个POST 请求。
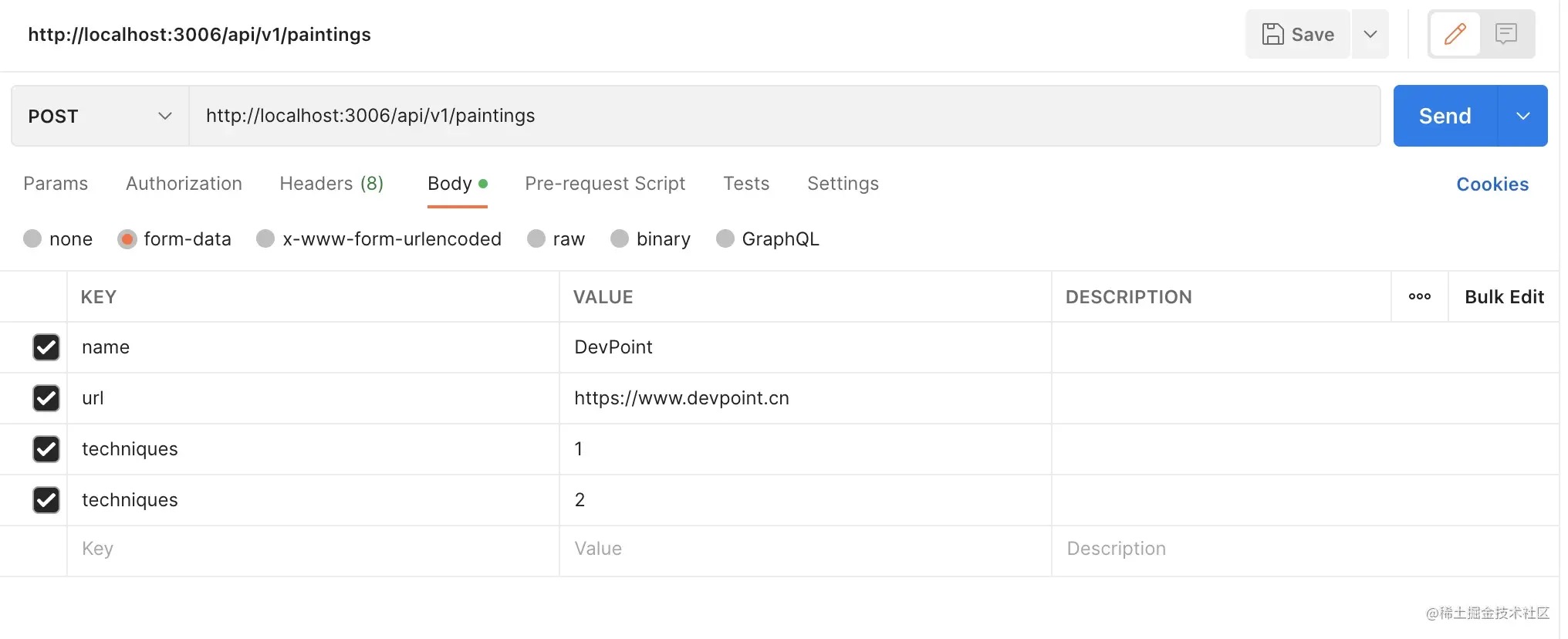
配置好参数,点击发送,看到响应如下:
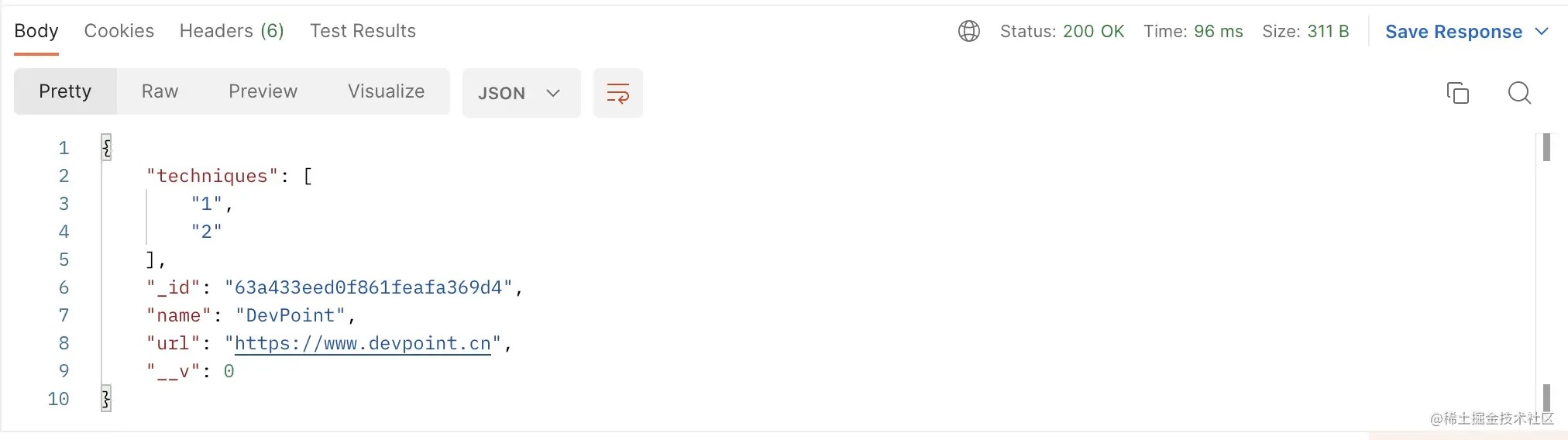
至此一个新的记录已经创建了,可以去数据库中查看。或者返回浏览器刷新 http://localhost:3006/api/v1/paintings,可以看到如下数据:

至此一个读取、写入接口完成了。
实施 GraphQL

GraphQL 究竟是什么?
GraphQL 的力量来自一个简单的想法,不是在服务器上定义响应的结构,而是将灵活性赋予了客户端。每个请求都指定了它想要返回的字段和关系,而 GraphQL 将构建一个为这个特定请求量身定制的响应。好处:只需要一次往返即可获取所有可能跨越多个 REST 端点的复杂数据,同时只返回实际需要的数据,仅此而已。
GraphQL 解决了传统 REST API 可能面临的一些痛点,如:
- 过度获取:响应中有不使用的数据。
- 取材不足:没有足够的数据来调用端点,导致需要调用第二个端点。
在这两种情况下,它们都可能带来性能问题:要么使用比理想情况更多的带宽,要么发出比理想情况更多的 HTTP 请求。
在一个完美的世界里,这些问题永远不会出现;将拥有完全正确的端点来为产品提供完全正确的数据。
当扩展和迭代产品时,经常会出现这些问题。在页面上使用的数据经常发生变化,并且为每个组件维护一个具有完全正确数据的单独端点的成本变得过高。
因此,最终会在没有太多端点和让端点最适合每个组件的需求之间做出折衷。这将导致在某些情况下过度获取(端点将提供比一个特定组件所需的数据更多的数据),并在其他一些情况下导致获取不足(将需要调用第二个端点)。
开始使用 GraphQL
首先,需要安装相应的依赖项。
yarn add graphql apollo-server-hapi
Graphql 是 graphql 的主要包,apollo-server-hapi 是 Hapi 服务器和 GraphQL 之间的粘合剂。
让项目根目录下创建一个名新的件夹 graphql,并在其目录下创建文件 PaintingType.js,代码如下:
const graphql = require("graphql");
const { GraphQLObjectType, GraphQLString } = graphql;
const PaintingType = new GraphQLObjectType({
name: "Painting",
fields: () => ({
id: { type: GraphQLString },
name: { type: GraphQLString },
url: { type: GraphQLString },
techniques: { type: GraphQLString },
}),
});
module.exports = PaintingType;
代码创建了一个新的 GraphQLObjectType,定义的几乎所有 GraphQL 类型都是对象类型。对象类型有一个名称,但最重要的是描述它们的字段。GraphQL 是一种静态类型语言,这意味着必须为字段声明类型,代码中声明了所有字段类型都是 GraphQLString。
现在需要为创建的 PaintingType 提供查询操作,在目录 graphql 创建文件 schema.js,代码如下:
const graphql = require("graphql");
const PaintingType = require("./PaintingType");
const { GraphQLObjectType, GraphQLString, GraphQLSchema } = graphql;
const Painting = require("./../models/Painting");
const RootQuery = new GraphQLObjectType({
name: "RootQuery",
fields: {
painting: {
type: PaintingType,
args: { id: { type: GraphQLString } },
resolve(parent, args) {
// 保存数据逻辑
return Painting.findById(args.id);
},
},
},
});
module.exports = new GraphQLSchema({
query: RootQuery,
});
上述代码将提供给服务器的根查询,字段部分现在更加复杂了,正在传递带有类型 PaintingType 和 args 字段的字段名称。那么如何找到一条 painting 特定的记录,需要某种参数来排序,在这种情况下,通常是 id。
接下来,resolve 是带有两个参数的函数,parent 以及 args。
只是为了说明,GraphQL 查询如下所示:
{
painting(id:20){
name
}
}
painting 查询来自 PaintingType.js 如何传递一个参数,这是 resolve() 中的 args 参数,参数 parent 将用于更复杂的查询,在这些查询中有更多的嵌套。
接下来导出根查询并将其传递给 Hapi 服务器, GraphQLSchema 类型是传递给服务器的根查询/模式定义。
module.exports = new GraphQLSchema({
query: RootQuery,
});
回到 server.js,增加 GraphQL 和 schema.js 相关的逻辑。
const { graphiqlHapi, graphqlHapi } = require("apollo-server-hapi");
const schema = require("./graphql/schema");
接下来需要注册 hapi-graphql 插件,在 server.register({}) 中,传递了 GraphQL 配置。
await server.register({
plugin: graphiqlHapi,
options: {
path: "/graphiql",
graphiqlOptions: {
endpointURL: "/graphql",
},
route: {
cors: true,
},
},
});
安装了 graphiql 插件,注意它是 graphiql 而不是 graphql。接下来让注册一个新插件:graphqlHapi,它包含之前制作的模式。
await server.register({
plugin: graphqlHapi,
options: {
path: "/graphql",
graphqlOptions: {
schema,
},
route: {
cors: true,
},
},
});
现在,打开浏览器,输入 http://localhost:3006/graphiql。
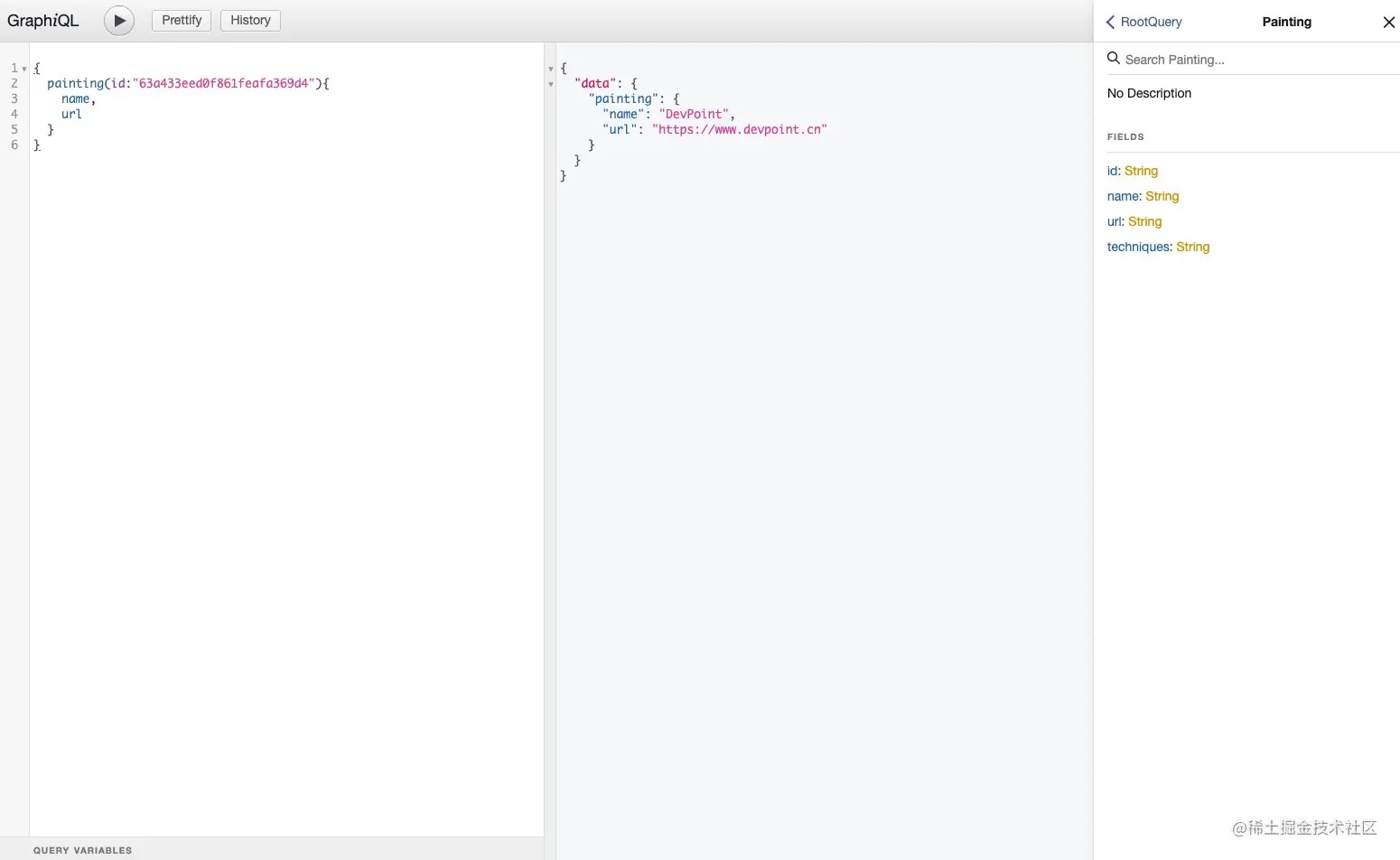
接下来在左侧输入查询语句:
{
painting(id:"63a433eed0f861feafa369d4"){
name,
url
}
}
执行之后结果如图:
至此,GraphQL 已经添加到项目中了,后续需要根据最新的版本优化代码。