Docker 无法启动 Failed to start LSB: Create lightweight, portable, self-sufficient containers.
解决办法执行以下命令:
wget -qO- https://get.docker.com/ | shDocker安装完启动时提示Failed to start docker.service: Unit docker.service is masked.
解决办法是按照顺序执行以下三条命令:
systemctl unmask docker.service
systemctl unmask docker.socket
systemctl start docker.service量子计算是利用量子力学定律解决传统计算机无法解决的庞大或复杂问题的过程。量子计算机依靠量子位来运行和解决多维量子算法。
量子计算利用量子理论的原理解决数学问题并运行量子模型。它用于模拟的一些量子系统包括光合作用、超导性和复杂的分子结构。
量子计算基本概念包括量子位、叠加、纠缠和量子干涉。
什么是量子位?
量子位或量子位是量子计算中信息的基本单位。有点像传统计算中的传统二进制位。
量子位利用叠加来同时处于多种状态。二进制位只能表示 0 或 1。量子位可以是 0 或 1,也可以是 0 和 1 两种状态叠加的任意部分。
量子比特是由什么组成的?答案取决于量子系统的架构,因为有些系统需要极冷的温度才能正常运行。量子位可以由捕获的离子、光子、人造或真实原子或准粒子制成,而二进制位通常是硅基芯片。
什么是叠加?
为了解释叠加态,有些人想到了薛定谔的猫,而另一些人则指出了抛硬币时硬币在空中的瞬间。
简而言之,量子叠加是量子粒子是所有可能状态的组合的一种模式。当量子计算机测量和观察每个粒子时,粒子继续波动和移动。
约翰·多诺霍(John Donohue)大学科学外展经理表示,关于叠加态(而不是同时聚焦两件事)更有趣的事实是能够以多种方式观察量子态,并提出不同的问题。滑铁卢量子计算研究所。也就是说,量子计算机不必像传统计算机那样顺序执行任务,而是可以运行大量并行计算。
这大约是我们在推出方程之前所能得到的最简化的结果。但最重要的一点是,这种叠加可以让量子计算机“同时尝试所有路径”。
什么是纠缠?
量子粒子能够相互对应测量,当它们处于这种状态时,称为纠缠。在纠缠期间,一个量子位的测量可用于得出有关其他单位的结论。纠缠有助于量子计算机解决更大的问题并计算更大的数据和信息存储。
什么是量子干涉?
当量子位经历叠加时,它们自然也会经历量子干涉。这种干扰是量子位以某种方式崩溃的概率。由于干扰的可能性,量子计算机致力于减少干扰并确保结果准确。
大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型。这些模型使用包括书籍、文章、网站和其他来源的广泛数据集进行训练。通过分析数据中的统计模式,大型语言模型可以预测给定输入后最可能出现的单词或短语。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
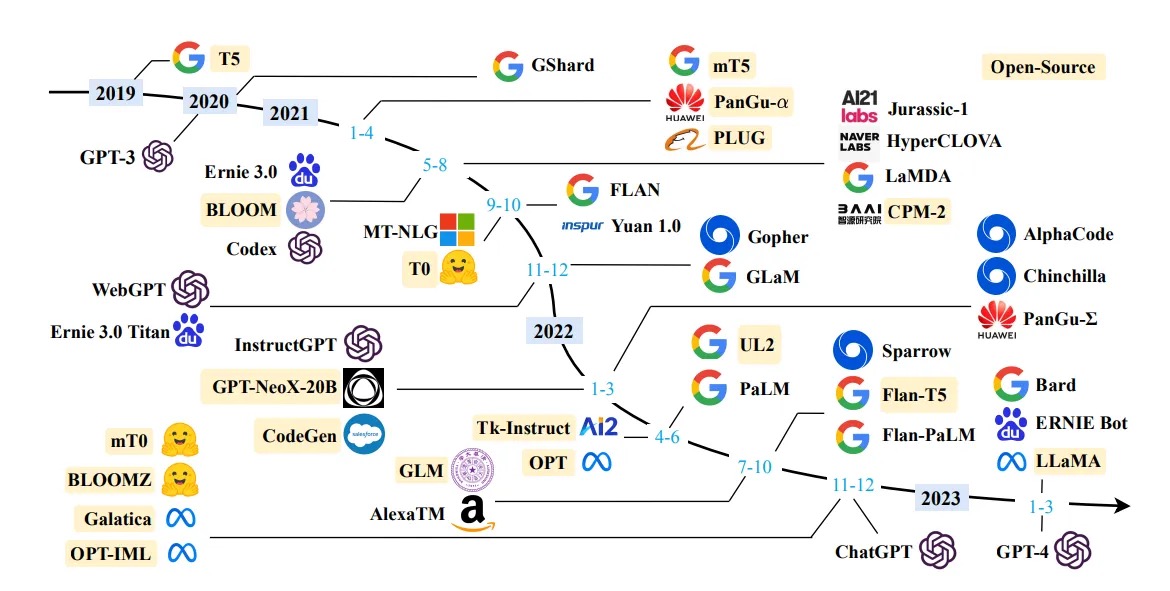
通过利用大型语言模型 (LLM),可以合并特定领域的数据来有效地解决查询。当处理模型在初始训练期间无法访问的信息(例如公司的内部文档或知识库)时,这变得特别有利。
LangChain 是一个AI开发功能强大的且免费的框架,经过精心设计,使开发人员能够创建由语言模型(尤其是大型语言模型 LLM)的力量驱动的应用程序。
LangChain 是一个框架,它一直是我作为开发者旅途中的规则改变者。 LangChain 是一个独特的工具,它利用大语言模型(LLMs)的力量为各种使用案例构建应用程序。Harrison Chase 的这个创意于 2022 年 10 月作为开源项目首次亮相。从那时起,它就成为 GitHub 宇宙中一颗闪亮的明星,拥有高达 42,000 颗星,并有超过 800 名开发者的贡献。
LangChain 就像一位大师,指挥着 OpenAI 和 HuggingFace Hub 等 LLM 模型以及 Google、Wikipedia、Notion 和 Wolfram 等外部资源的管弦乐队。它提供了一组抽象(链和代理)和工具(提示模板、内存、文档加载器、输出解析器),充当文本输入和输出之间的桥梁。这些模型和组件链接到管道链中,这让开发人员能够轻而易举地快速构建健壮的应用程序原型。本质上,LangChain 是 LLM 交响乐的指挥家。
LangChain 彻底改变了多种应用程序的开发流程,包括聊天机器人、生成问答(GQA)和摘要。通过将来自多个模块的组件无缝链接在一起,LangChain 能够围绕大语言模型的力量创建卓越的应用程序。
LangChain 的真正优势在于它的七个关键模块:
- 模型:这些是构成应用程序主干的封闭或开源 LLM
- 提示:这些是接受用户输入和输出解析器的模板,这些解析器格式化 LLM 模型的输出。
- 索引:该模块准备和构建数据,以便 LLM 模型可以有效地与它们交互。
- 记忆:这为链或代理提供了短期和长期记忆的能力,使它们能够记住以前与用户的交互。
- 链:这是一种在单个管道(或“链”)中组合多个组件或其他链的方法。
- 代理人:根据输入决定使用可用工具/数据采取的行动方案。
- 回调:这些是在 LLM 运行期间的特定点触发以执行的函数。
了解更多:官方文档
Docker 让开发和部署变得容易了,正因为容易导致不经意的就在不断添加新的 docker 映像、容器等。这些都将占用了系统上的宝贵空间,而且是一直在快速地增加。所以有必要清理Docker环境,把一些不在使用的 Docker 资源清理掉。
首先使用 df 命令查看磁盘的使用情况:
docker system df
返回的结果如下:
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 33 8 16.8GB 16.39GB (97%)
Containers 9 1 37.43kB 36.44kB (97%)
Local Volumes 7 2 0B 0B
Build Cache 507 0 21.19GB 21.19GB
请注意,Reclaimable 就是可以恢复的大小,它是通过从总图像大小中减去活动图像的大小来计算的。
接下来就可以使用以下方法来清理:
- 清理停止的容器:使用
docker rm命令清理停止的容器,命令格式为:docker rm <container_id>。 - 清理未使用的镜像:使用
docker image prune命令清理未使用的镜像,命令格式为:docker image prune。 - 清理无用的数据卷:使用
docker volume prune命令清理无用的数据卷,命令格式为:docker volume prune。 - 清理未使用的网络:使用
docker network prune命令清理未使用的网络,命令格式为:docker network prune。 - 清理Docker缓存:使用
docker builder prune命令清理Docker缓存,命令格式为:docker builder prune。 - 清理Docker日志:使用
docker logs命令查看容器日志,确认无用日志后,使用truncate命令清空日志文件,命令格式为:truncate -s 0 <logfile>。
开发视频网站需要使用多种技术,对于多用户的视频网站来说除了技术之外还有运维相关的技术。下面是开发视频网站需要的一些技术:
- 前端技术:视频网站的前端通常需要使用
HTML、CSS、JavaScript等技术来实现用户界面和交互效果。同时,为了提高用户的体验和响应速度,也需要使用前端框架,如React、Vue等。 - 后端技术:后端需要使用一种或多种服务器端编程语言来实现业务逻辑,如Python、PHP、Go、Java等。同时,也需要使用一种或多种数据库来存储用户信息、视频数据等内容,如MySQL、MongoDB等。
- 视频处理技术:需要支持视频的上传、转码、截取等功能。这需要考虑大文件的断点续传问题,视频处理技术可以考虑
FFmpeg、Handbrake等来实现。 - CDN技术:视频网站通常需要使用CDN技术来加速视频的加载速度,降低服务器的压力。CDN可以将视频数据缓存到全球各地的节点,用户可以从离自己最近的节点获取视频数据,提高了视频的加载速度和用户体验。
- 安全技术:视频网站需要保障用户的隐私和安全,如登录、注册等功能需要使用加密技术来保护用户信息的安全。同时,视频网站也需要对用户上传的视频进行审核和过滤,防止不良内容的传播。
- 视频播放技术:视频网站需要支持高质量的视频播放,需要使用流媒体协议,如
HTTP Live Streaming (HLS)、Dynamic Adaptive Streaming over HTTP(DASH)等。同时,还需要支持多种视频格式,如MP4、AVI等。 - 社交媒体技术:视频网站通常需要支持社交媒体功能,如用户之间的关注、评论、点赞等。这需要使用社交媒体技术,如
OAuth2.0、OpenID Connect等来实现。 - 移动端开发技术:随着移动设备的普及,视频网站需要支持多种移动设备,如手机、平板等。因此,视频网站需要使用移动端开发技术,如React Native、Flutter等,同时还需要考虑响应式设计、移动端适配等问题。
- AI技术:使用AI技术,如机器学习、计算机视觉等来实现自动化审核、内容推荐等功能,提高用户体验和运营效率。
总之,视频网站的开发需要使用多种技术支持,这些技术需要不断地更新和优化,才能满足用户不断变化的需求和期望。因此,开发视频网站需要开发人员具备丰富的技术知识和实践经验,能够不断地学习和更新技术,提高开发效率和质量。
下面是一些可能用得上的开源视频网站框架和平台:
- Video.js:一个开源的HTML5视频播放器框架,提供了多种功能和插件,如字幕、广告等。
- Kaltura:一个开源的视频管理平台,提供了视频上传、转码、存储、管理等功能,同时也支持视频播放和广告等功能。
- YouPHPTube:一个开源的PHP视频网站框架,提供了视频上传、转码、存储、管理等功能,同时还支持用户注册、评论、点赞等社交媒体功能。
- MediaDrop:一个开源的视频网站平台,使用Python开发,提供了视频上传、转码、存储、管理等功能,同时也支持社交媒体功能和API接口等。
- PeerTube:一个基于WebTorrent协议的开源视频网站平台,使用Node.js和Vue.js开发,提供了视频上传、转码、存储、管理等功能,同时也支持社交媒体功能和P2P视频传输等。
这些开源视频网站框架和平台都提供了丰富的功能和插件,可以根据实际需求进行选择和定制。同时,它们也提供了开放的API接口和文档,方便开发人员进行二次开发和集成。
Docker 动态扩容指的是在应用程序负载增加时,自动增加 Docker 容器实例的数量,以应对高负载的需求。以下是几种 Docker 动态扩容的方法:
- Docker Swarm:Docker Swarm 是 Docker 官方提供的容器编排工具,它支持动态扩容和缩容,可以根据实际负载情况自动增加或减少 Docker 容器实例的数量。使用 Docker Swarm,可以通过命令行或 API 来创建和管理 Docker 服务,从而使容器的部署和管理更加方便和高效。
- Kubernetes:Kubernetes 是 Google 开源的容器编排工具,也支持自动伸缩。它提供了强大的自动化功能,可以通过自定义规则来调整容器的数量,以确保应用程序的高可用性和可扩展性。Kubernetes 还支持水平自动扩容和垂直自动扩容,可以根据容器内存使用率、CPU 使用率等指标来自动调整容器的数量。
- Docker Compose:Docker Compose 是 Docker 官方提供的容器编排工具,它支持通过命令行或 API 来创建和管理多个 Docker 容器,也可以通过使用 Docker Compose 文件来定义应用程序的各个服务以及它们之间的依赖关系。Docker Compose 还支持自动伸缩和负载均衡,可以根据应用程序负载情况动态调整容器的数量。
- 自定义脚本:如果以上方法不适用于您的需求,可以编写自定义脚本来实现容器的动态扩缩容。例如,可以编写 Python 脚本来监测容器的负载情况,当负载达到一定阈值时,自动增加容器实例的数量。这种方法需要一定的编程技能和经验,但可以根据具体需求进行定制。
Kubernetes 与 Docker Swarm
容器编排正在快速发展,Kubernetes 和 Docker Swarm 是该领域的两大参与者。Kubernetes 和 Docker Swarm 都是用于在集群内部署容器的重要工具。Kubernetes 和 Docker Swarm 在该领域有许多突出的利基 USP 和专业人士,它们将继续存在。尽管他们两人实现目标的方式截然不同且独特,但归根结底,他们的终点仍然很近。

Kubernetes 概述
Kubernetes 基于谷歌多年在大规模生产中运行工作负载的经验。根据Kubernetes 网站,“Kubernetes 是一个开源系统,用于自动部署、扩展和管理容器化应用程序。”
它将构成应用程序的容器分组为逻辑单元,以便于管理和发现。Kubernetes 建立在谷歌 15 年运行生产工作负载的经验之上,并结合了来自社区的最佳创意和实践。
Docker Swarm 概述
Docker swarm 是 Docker 自带的容器的编排系统。它使用标准的 Docker API 和网络,可以很容易地进入您已经在使用 Docker 容器的环境。Docker Swarm 旨在围绕四个关键原则工作:
- 不那么杂乱/繁重,只用工作方法
- Docker Swarm 没有单点故障选项
- 由于自动生成安全证书而安全。
- 轻松兼容向后版本。
总之,以上是 Docker 动态扩容的常见方法,可以根据实际需求选择合适的方案。Docker Swarm、Kubernetes 和 Docker Compose 是 Docker 官方提供的容器编排工具,支持自动扩缩容,而自定义脚本可以根据具体需求进行定制。无论使用哪种方法,都需要对容器的资源利用情况进行监测和调整,以确保应用程序的高可用性和可扩展性。
链表相加是指将两个链表表示的数相加,得到一个新的链表表示的结果。假设两个链表的每个节点都表示一位数字,且是逆序存储的(即链表的尾部表示数字的最高位),那么可以按照以下步骤来实现链表相加:
- 定义一个 ListNode 类来表示链表的节点,其中包含一个
val属性表示节点的值,以及一个next属性表示指向下一个节点的指针。 - 定义一个
addTwoNumbers函数,接收两个链表作为参数。 - 创建一个新链表
result,表示相加的结果。同时定义两个指针p和q分别指向两个链表的头节点,以及一个指针curr指向结果链表的头节点。 - 对于每一位数字,将
p和q指向的节点的值相加,并加上前一位数字的进位值,得到一个新的进位值和相加后的值。将该值存储到结果链表中,并将指针p、q和curr向后移动。 - 如果有任何一个链表已经到达了末尾,则在计算下一位数字时只考虑另一个链表的值,并将前一位的进位值加到结果中。如果计算完所有位数后,前一位仍然有进位,则需要将进位值添加到结果链表的末尾。
下面是具体的实现代码:
class ListNode {
constructor(val, next = null) {
this.val = val;
this.next = next;
}
}
function addTwoNumbers(l1, l2) {
let p = l1;
let q = l2;
let carry = 0; // 进位值
let result = new ListNode(0);
let curr = result;
while (p !== null || q !== null) {
const x = p ? p.val : 0;
const y = q ? q.val : 0;
const sum = x + y + carry;
carry = Math.floor(sum / 10);
curr.next = new ListNode(sum % 10);
curr = curr.next;
if (p) p = p.next;
if (q) q = q.next;
}
if (carry > 0) {
curr.next = new ListNode(carry);
}
return result.next;
}
在上述代码中,首先定义了一个 ListNode 类来表示链表的节点。在 addTwoNumbers 函数中,初始化了两个指针 p 和 q 分别指向两个链表的头节点,同时初始化了一个进位值 carry 和结果链表 result。然后,循环遍历两个链表,计算每一位数字的相加结果,并将结果存储到结果链表中。最后,如果前一位数字有进位,则需要将进位值添加到结果链表的末尾。
可以使用上述代码的时间复杂度是 $O(\max(m,n))$,其中 $m$ 和 $n$ 分别是两个链表的长度。这是因为需要遍历两个链表,并对每一位数字进行相加。空间复杂度也是 $O(\max(m,n))$,因为需要创建一个新的链表来存储相加的结果。
下面是一个示例,演示如何使用上述代码来计算链表相加:
const l1 = new ListNode(3, new ListNode(4, new ListNode(3)));
const l2 = new ListNode(5, new ListNode(6, new ListNode(4)));
const result = addTwoNumbers(l1, l2);
console.log(result);
上述示例中输出的结果为:
ListNode {
val: 8,
next: ListNode { val: 0, next: ListNode { val: 8, next: null } }
}
代码审查(Code Review)是项目开发中常见的流程之一,而这里要跟大家介绍的是代码审计,在区块链里面通常需要对智能合约进行审计已确保合约逻辑的正常。
代码审计(Code Audit)和代码审查(Code Review)虽然都是针对代码的质量评估,但是两者并不是完全相同的概念。
- 代码审查(Code Review) 是指开发人员在编写代码之后,由其他人员(通常是同事或团队成员)对其代码进行检查和评估,以发现可能存在的错误或潜在的问题。它是一种常规的实践,以确保代码的质量和可读性,以及确保代码符合最佳实践。
- 代码审计(Code Audit) 是一种更全面的安全评估方法,它是对代码的系统性评估,以发现潜在的漏洞、安全隐患和其他风险。它是一种主要用于评估代码的安全性的方法,其目的是发现任何可能导致安全问题的漏洞和缺陷。
在实践中,代码审查通常是在开发过程中完成的,而代码审计通常是在应用程序发布之前或在代码更改较大时进行的。两种方法都是非常重要的,可以帮助确保代码的质量和安全性,并减少在应用程序中出现潜在问题的风险。
下面是一些可以帮助进行 Node.js 代码审计的步骤:
了解应用程序的架构和设计
在开始代码审计之前,需要对应用程序的架构和设计有一定的了解。这可以帮助更好地理解应用程序的代码结构和组件之间的交互。
确定应用程序的安全需求
在进行代码审计之前,需要明确应用程序的安全需求。这可以帮助了解应用程序中哪些部分可能存在安全漏洞,并优先处理这些漏洞。
熟悉常见的攻击方式和漏洞类型
在进行代码审计之前,需要了解常见的攻击方式和漏洞类型,以帮助更好地识别潜在的安全问题。
代码静态分析
使用代码静态分析工具可以帮助自动化一部分代码审计任务。这些工具可以扫描代码并标识潜在的漏洞和安全问题。
代码动态分析
代码动态分析可以帮助您模拟攻击并测试应用程序的安全性。例如,可以使用漏洞扫描工具来模拟攻击,并识别应用程序中可能存在的漏洞。
审计第三方模块
当使用第三方模块时,这些模块可能包含潜在的漏洞和安全问题。因此,在进行代码审计时,应该审查所有使用的第三方模块,并确保它们是最新的版本,并且没有任何已知的漏洞。
审计数据库和文件系统
数据库和文件系统可能是应用程序中最敏感的组件之一。在进行代码审计时,应该仔细审查与数据库和文件系统交互的代码,并确保所有数据都是安全处理的。
总之,Node.js 代码审计需要仔细的计划和精细的技能。在进行代码审计时,应该始终关注应用程序的安全性,并尽可能地使用各种工具和技术来确保应用程序的安全性。
SSL(Secure Sockets Layer)证书是一种用于加密互联网上的数据传输的安全协议。网站部署 SSL 证书的主要目的是保证用户的数据在传输过程中不会被窃取或篡改。具体来说,部署 SSL 证书可以带来以下几个方面的好处:
- 加密数据传输:SSL 证书可以对数据进行加密处理,使得在数据传输过程中无法被窃听或篡改,以有效保护用户的个人信息和敏感数据不被黑客窃取。
- 确认网站身份:SSL 证书可以对网站的身份进行验证,确保用户所访问的网站是真实可信的,可以有效防止仿冒网站的出现,提高用户的安全感和信任度。
- 提高搜索引擎排名:Google 等搜索引擎会考虑网站是否采用 SSL 证书作为搜索排名的一个因素。部署 SSL 证书可以提高网站的搜索排名,提高流量和用户访问量。
综上所述,网站部署 SSL 证书是保障用户信息安全、提高网站可信度和搜索排名的重要手段。特别是在涉及到用户个人信息、支付信息等敏感数据的网站上,部署 SSL 证书更是必不可少的安全措施。
前面介绍SSL是一种加密传输协议,主要目的是确保在互联网上传输的数据不被窃取或篡改。SSL 基于公钥加密技术和对称密钥加密技术,通过数字证书来验证网站的身份,并对数据进行加密和解密。
SSL 加密大致原理如下:
- 客户端向服务器发送请求,请求建立 SSL 连接。
- 服务器把自己的公钥和证书发给客户端。证书中包含了网站的名称、公钥、有效期等信息,客户端可以通过证书验证网站的身份是否合法。
- 客户端使用服务器公钥加密生成一个随机数,并发送给服务器。
- 服务器使用私钥解密客户端发送的随机数,并使用客户端发送的随机数和服务器自己生成的随机数生成一个密钥。这个密钥即为会话密钥,用于加密和解密在本次连接中的所有数据。
- 服务器将生成的会话密钥通过公钥加密,并发送给客户端。
- 客户端使用会话密钥对数据进行加密,并发送给服务器。
- 服务器使用会话密钥对数据进行解密,并返回给客户端。
通过以上步骤,客户端和服务器就建立了一个 SSL 安全连接,所有传输的数据都会经过加密处理,确保数据的机密性和完整性。同时,通过证书验证,确保连接的安全和可信。虽然 SSL 是一种安全性较高加密协议,但并不是完全不可破解的。
SSL 可能被破解的原因包括以下几点:
- 密码破解:攻击者可以使用暴力破解等手段猜测密码。如果 SSL 的密码不够复杂,那么攻击者就有可能成功破解密码。
- 中间人攻击:攻击者可以通过 DNS 劫持、ARP 欺骗等手段,篡改 SSL 握手过程中的证书和密钥,使得数据传输的过程中被篡改或窃取。
- SSL 版本漏洞:SSL 协议本身存在漏洞,攻击者可以利用这些漏洞攻击 SSL 连接。
- 系统漏洞:操作系统或网络设备的漏洞可能会影响 SSL 连接的安全性。
总之,SSL 加密技术虽然有一定的安全性,但并不意味着万无一失,也需要在实践中不断加强安全防护,才能更好地保障数据传输的安全。现在很多浏览器对于没有 SSL 的证书的网站标记为不安全,其实部署成本不高,阿里云和腾讯云每个账号都有20个免费数据,或者可以自己搭建。
PyTorch是一个基于Python的科学计算库,主要用于深度学习研究和开发。PyTorch提供了丰富的工具和接口,可以用于构建、训练和部署深度学习模型。
在Docker上安装PyTorch环境需要的内存取决于具体的应用场景和使用方式,但通常需要至少 2GB 的内存来运行PyTorch及其相关库。如果要使用 GPU 进行深度学习训练,还需要安装相应的 GPU 驱动和 CUDA 工具包,并且需要更多的内存和显存。
当然,对于 Docker 来说,可以通过设置资源限制来控制容器所占用的内存,这样可以避免应用程序占用过多的内存导致系统出现问题。可以通过Docker的 -m 选项来设置容器最大可以使用的内存限制,例如:
docker run -it -m 2g pytorch/pytorch:latest
上述命令会启动一个PyTorch容器,并将其最大内存限制设置为 2GB。这样即使应用程序出现了内存泄漏等问题,也不会占用过多的系统资源。
JavaScript中的 this 是一个非常重要的概念,它指向当前执行上下文的对象。由于JavaScript是一门动态语言,this 的指向在运行时才能确定,可能会因为调用方式和执行环境的不同而有所变化。
this 的指向可以通过四种调用方式来决定:
- 作为函数调用时,
this指向全局对象(浏览器中为window对象,Node.js中为global对象)。 - 作为方法调用时,
this指向调用该方法的对象。 - 使用
call()或apply()方法调用时,this指向第一个参数传入的对象。 - 使用
new关键字调用构造函数时,this指向新创建的对象。
除了上述四种方式,还有一些特殊情况需要注意,例如箭头函数中的 this 指向是定义函数时的上下文,不会随着调用环境的改变而改变。
总之,JavaScript中的this是一个非常灵活和有用的概念,可以根据不同的调用方式来决定其指向,需要开发者在实际开发中灵活应用。
举一个具体的例子,假设有一个对象 person,它有两个方法 sayHello 和 introduce :
const person = {
name: "Quintion",
age: 32,
sayHello() {
console.log(`Hello, my name is ${this.name}`);
},
introduce() {
console.log(`I'm ${this.age} years old.`);
},
};
如果以方法调用的方式调用 sayHello() 和introduce():
person.sayHello(); // Hello, my name is Quintion
person.introduce(); // I'm 32 years old.
此时 this 分别指向 person 对象,因为这两个方法是在 person 对象中定义的。
如果以函数调用的方式调用 sayHello() 和introduce():
const sayHello = person.sayHello;
const introduce = person.introduce;
sayHello(); // Hello, my name is undefined
introduce(); // I'm undefined years old.
此时 this 指向全局对象,因为函数调用是在全局上下文中执行的。由于全局对象并没有 name 和 age 属性,所以输出结果为 undefined。
如果将上面的函数使用 call() 方法来调用,如下:
const sayHello = person.sayHello;
const introduce = person.introduce;
sayHello.call(person); // Hello, my name is Quintion
introduce.call(person); // I'm 32 years old.
此时 this 指向 person 对象,因为在 call() 方法的第一个参数中传入了 person 对象。
需要注意的是,如果在严格模式下使用函数调用方式,
this指向的是undefined,而非全局对象。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它以文本格式来表示数据,可以被各种编程语言解析和生成。下面是JSON对象的基础知识:
- 数据格式:JSON数据格式由两种结构组成:
键值对和数组。键值对表示对象,键和值之间使用冒号分隔,多个键值对之间使用逗号分隔,整个对象使用花括号包含。数组表示一个有序的值的列表,多个值之间使用逗号分隔,整个数组使用方括号包含。 - 表示方式:在JavaScript中,JSON对象是一种原生的JavaScript对象,可以使用字面量表示法来创建。例如,
let jsonObj = { "name": "张三", "age": 20 };就是一个JSON对象,其中包含了两个键值对。 - 对象的方法:JSON对象提供了两个方法,分别是
JSON.stringify()和JSON.parse()。JSON.stringify()方法用于将JavaScript对象转换成JSON字符串,而JSON.parse()方法用于将JSON字符串解析成JavaScript对象。 - 对象的应用:JSON对象在前端开发中非常常见,它可以用于数据的传输和存储,也可以用于数据的解析和展示。例如,在前端与后端进行数据交互时,通常会将数据格式化为JSON字符串进行传输。在前端开发中,我们还可以通过
Ajax请求获取JSON数据,然后使用JavaScript代码对数据进行解析和展示。 - 对象的序列化和反序列化:JSON对象的
JSON.stringify()方法可以将JavaScript对象序列化成JSON字符串,该方法还可以接收一个可选的第二个参数,用于控制序列化的过程,例如过滤掉某些属性或者添加额外的空格等。JSON.parse()方法可以将JSON字符串反序列化成JavaScript对象,该方法还可以接收一个可选的第二个参数,用于解析日期对象或自定义的解析函数等。 - 对象的嵌套和复杂性:JSON对象可以嵌套,一个JSON对象的属性值也可以是一个JSON对象或者一个JSON数组。JSON数据可以非常复杂,包含嵌套的对象、数组、字符串、数字、布尔值、
null等各种类型。在实际应用中,我们需要根据实际情况来组织和解析JSON数据,保证数据的正确性和可读性。 - 对象的兼容性:JSON对象在大部分现代浏览器和JavaScript引擎中都有很好的支持,但是在一些旧版浏览器中可能会存在不兼容的情况。为了保证兼容性,可以使用第三方的JSON库,例如
JSON2.js等。
需要注意的是,在使用JSON对象时,需要遵守JSON数据格式的规范,例如键和值必须使用双引号包含,不支持注释等。此外,在解析JSON字符串时,还需要注意可能会存在的安全问题,例如恶意的JSON数据可能会导致XSS攻击等。
跨域请求,是前端开发比较常见的问题。通常为了提高的开发效率,项目开发过程中进行前后端分离,部署各自独立,就可能会出现前端后域名不一致,在通讯过程中就会出现跨域的问题。由于项目开发过程中涉及,借此机会对跨域问题进行整理。
下面也简单总结一下,有以下几种跨域方式:
JSONP(JSON with Padding)跨域:JSONP实现跨域的核心原理是利用<script>标签没有跨域限制的特性,通过在请求的URL中添加回调函数名称,服务器返回一个JavaScript函数的调用,并将需要传递的数据作为参数传递给该函数。该方式只支持GET请求,而且只能实现单向数据传输。CORS(Cross-Origin Resource Sharing)跨域:CORS是一种标准的跨域解决方案,它通过在服务端设置Access-Control-Allow-*头信息来实现跨域。该方式可以支持GET和POST等多种请求方式,而且可以双向通信,实现更灵活的数据传输。CORS需要浏览器和服务器同时支持。WebSocket跨域:WebSocket是一种新的协议,它可以在浏览器和服务器之间建立持久化的连接,从而实现双向实时通信。在跨域方面,WebSocket也需要服务器支持跨域。代理跨域:代理跨域是一种常见的解决方案,它的核心思想是在客户端和服务端之间加一个中间层,将客户端的请求先发送给中间层,中间层再将请求发送给服务端,待服务端响应后再将响应发送给客户端。因为是同源策略下的服务端请求,所以不存在跨域问题。postMessage跨域:postMessage是HTML5引入的一种消息传递机制,它可以让来自不同源的脚本建立通信渠道,从而实现跨域数据传输。但是该方式需要目标窗口明确设置监听事件,否则容易受到恶意攻击。
dApp指的是去中心化应用(Decentralized Application),是运行在区块链技术上的应用程序。与传统的应用程序不同,dApp是由智能合约(Smart Contract)编写的,可以在区块链网络上运行,实现去中心化、透明化、不可篡改等特点。
dApp的主要特点包括:
- 去中心化:dApp没有中心化的控制机构,应用程序代码和数据被分布在多个节点上,没有单点故障,可以实现自我运作和自治。
- 透明化:dApp的交易和数据记录都被记录在区块链上,任何人都可以查看和验证,保证了交易的公开和透明。
- 不可篡改性:dApp中的数据和代码都被记录在区块链上,一旦被记录,就无法被更改或删除,保证了数据和代码的不可篡改性。
- 自动化:dApp可以通过智能合约实现自动化的交易和管理,无需人为干预,减少了中间环节和成本。
dApp对去中心化非常重要,因为它们是在区块链技术基础上构建的应用程序,能够利用区块链技术的去中心化特点。去中心化是区块链技术的核心特点之一,它可以解决传统中心化系统中存在的安全、可靠性、透明性和可信度等问题。
在传统的中心化系统中,应用程序是由中心化机构控制和运营的,用户需要信任这些机构来保护他们的数据和交易。而在dApp中,应用程序运行在区块链网络中,由智能合约执行和控制,没有中心化的机构控制,保证了数据和交易的安全和可信度。此外,dApp中的交易和数据记录都被记录在区块链上,保证了交易的公开和透明。
因此,dApp是区块链技术的重要应用之一,能够通过去中心化的方式提供更加安全、透明、可信的应用程序,为数字世界的各种场景带来新的解决方案。
在 JavaScript 项目中,通常会使用许多不同的工具和框架,取决于具体的项目需求和开发团队成员的能力。以下是一些常用的工具和框架:
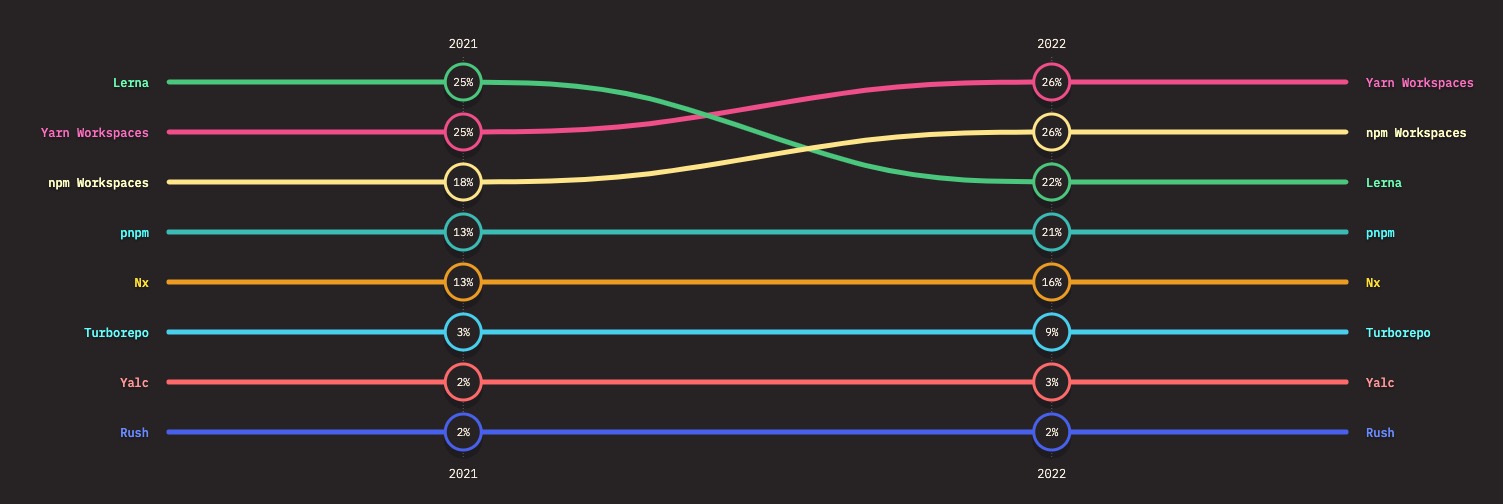
包管理工具
包管理 npm、yarn 工具可以用来安装、管理、升级和发布 JavaScript 包和模块。
- npm 是最常用的包管理工具,但是一些开发者也喜欢使用
- yarn 因为它具有更快的安装速度和更好的缓存机制。
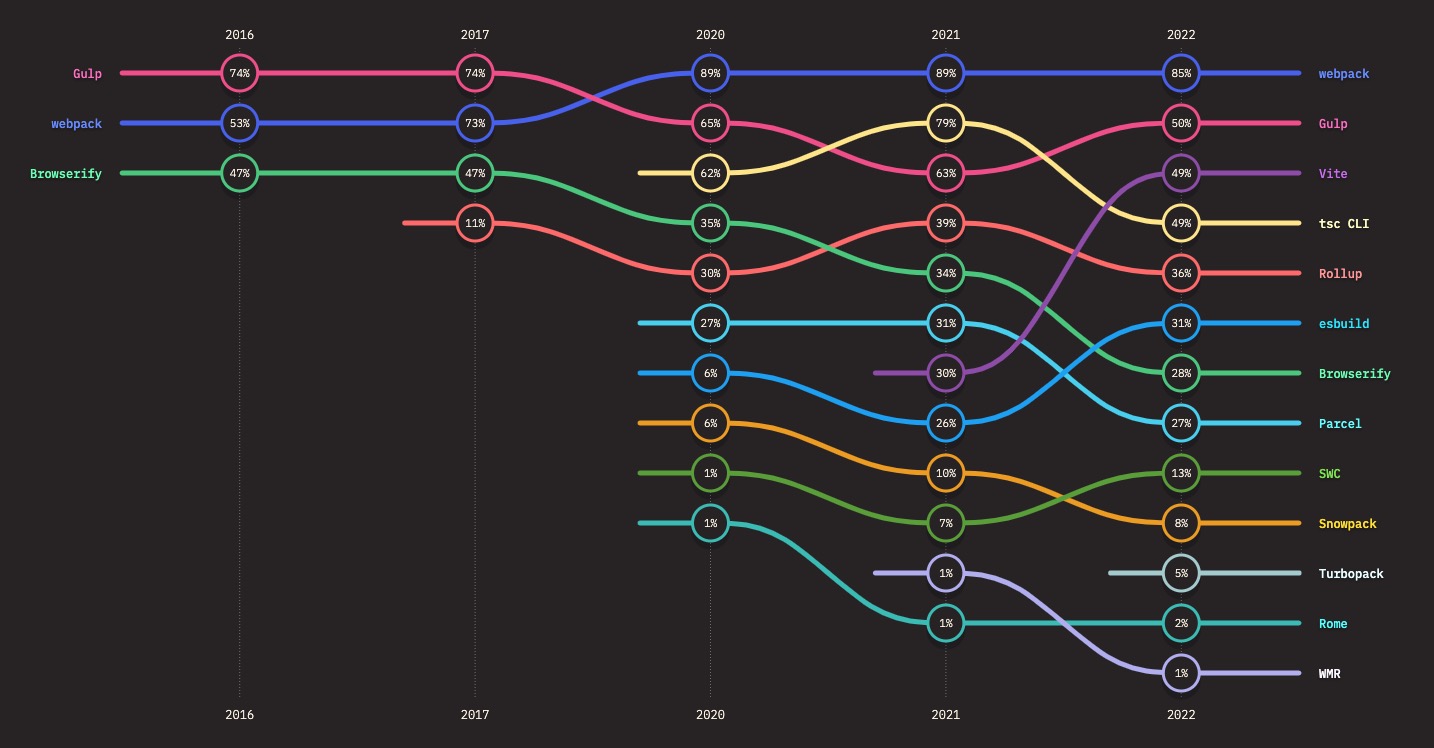
构建工具
构建工具 Webpack、Gulp、Rollup、Parcel 用来打包、压缩和优化 JavaScript 代码。Webpack 是最常用的构建工具之一,但是 Rollup 和 Parcel 也非常流行。这些工具通常可以自动处理依赖关系,并使用各种插件来实现不同的功能。
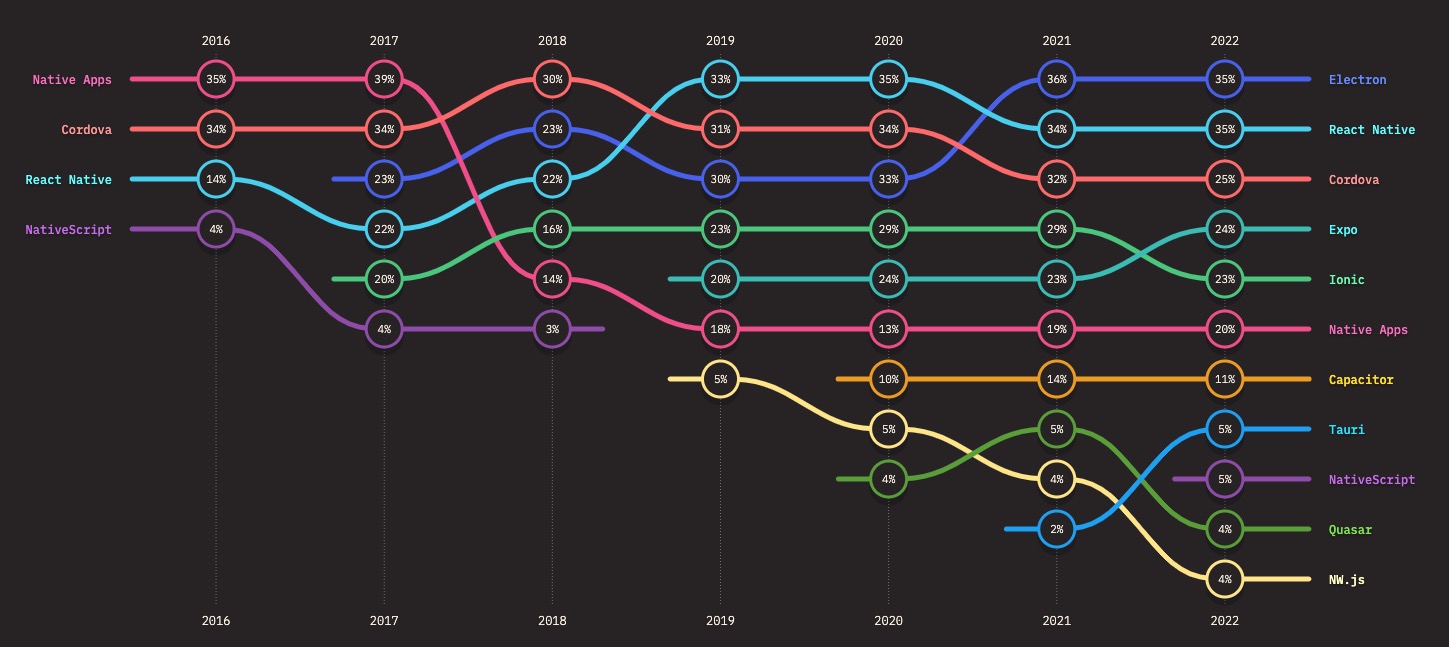
移动和桌面
移动端或者桌面APP开发框架 Electron、React Native、Cordova 是最长用的。
开发框架
开发框架React、Angular、Vue可以帮助开发者更轻松地构建复杂的 Web 应用程序。React 是最受欢迎的框架之一,但是 Angular 和 Vue 也非常流行。每个框架都有其独特的优点和用途,下面的数据对国外的开发者更有参考意义,国内应该VUE的份额占大头。
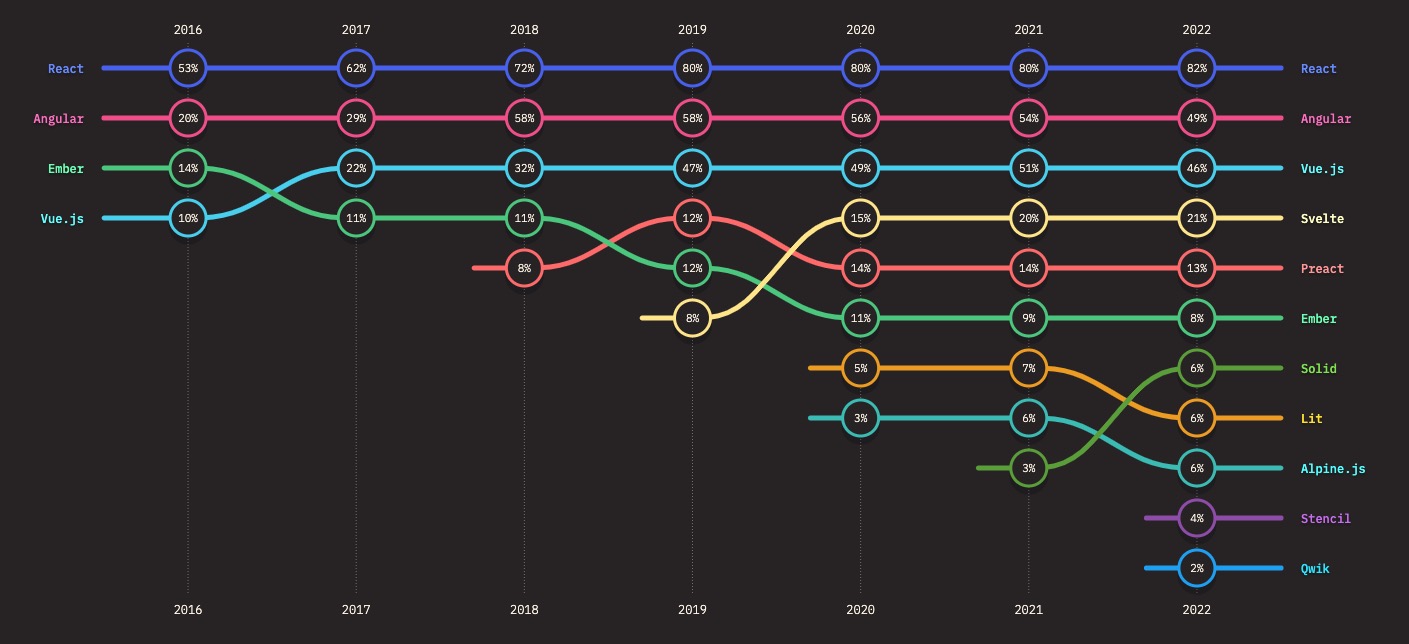
测试工具
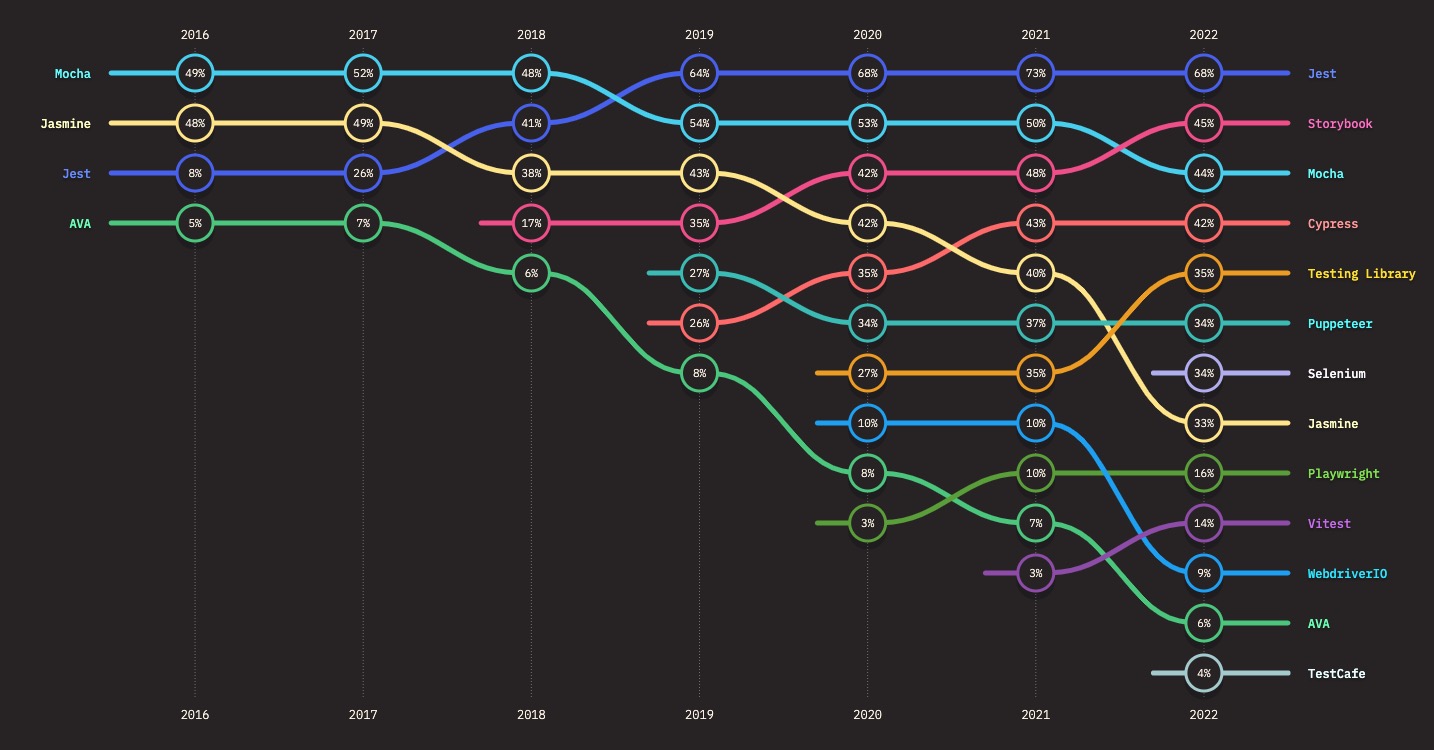
测试工具Jasmine、Mocha、Jest用来编写和运行 JavaScript 单元测试和端到端测试。Jasmine 和 Mocha 是最常用的测试框架之一,但是 Jest 在最近几年变得非常流行,去年成为最受欢迎的测试工具。
类型检查工具
类型检查工具TypeScript、Flow 帮助开发者在编写代码时检测类型错误。TypeScript 是最常用的类型检查工具之一,但是 Flow 也受到了许多开发者的欢迎。
文档工具
文档工具JSDoc、TypeDoc、ESDoc可以用来自动生成 JavaScript 代码文档。JSDoc 是最常用的文档工具之一,但是 TypeDoc 和 ESDoc 也非常流行。这些工具通常可以根据代码中的注释生成文档。
代码格式化工具
代码格式化工具Prettier、ESLint用来自动格式化 JavaScript 代码。Prettier 是最常用的代码格式化工具之一,但是 ESLint 也可以用来执行代码格式化和语法检查。
在ES6中,可以使用 class 关键字来定义一个类,然后使用 new 关键字创建该类的对象。
下面是一个简单的例子:
// 定义一个Person类
class Person {
// 构造函数,用于创建Person对象时初始化其属性
constructor(name, age) {
this.name = name;
this.age = age;
}
// 方法,用于返回Person对象的名字
getName() {
return this.name;
}
// 方法,用于返回Person对象的年龄
getAge() {
return this.age;
}
}
// 创建一个Person对象
const person = new Person("全栈工匠", 30);
// 调用Person对象的方法
console.log(person.getName()); // 全栈工匠
console.log(person.getAge()); // 30
在上面的例子中,首先使用 class 关键字定义了一个 Person 类,该类包含了一个构造函数和两个方法。然后使用 new 关键字创建了一个 Person 对象,并将其赋值给 person 变量。最后,通过调用 person 对象的两个方法来获取该对象的名字和年龄。
值得注意的是,在ES6中类是基于原型的,因此类的方法定义在类的原型对象上。另外,ES6中的类也支持继承,可以通过
extends关键字来创建一个子类,并且可以使用super关键字来调用父类的构造函数和方法。
对象在JavaScript中是一种非常重要的数据类型,它们有很多有用的方法,在平常项目开发中可以使用这些方法容易地处理对象。关于对象推荐阅读下面文章
在 JavaScript 中,可以通过数组来实现一个二叉堆。二叉堆分为最大堆和最小堆两种类型,本问将以最大堆为例子。
一个二叉堆可以看做是一颗完全二叉树,每个节点的值都大于等于其子节点的值(对于最大堆而言)。因此,在使用数组来实现二叉堆时,可以使用数组下标来表示完全二叉树的节点,并满足以下规则:
- 对于任意节点
i,其左子节点的下标为2i+1,右子节点的下标为2i+2。 - 对于任意节点
i,其父节点的下标为Math.floor((i-1)/2)。
接下来,可以使用数组来实现一个最大堆。具体而言,可以定义一个数组 arr 来保存堆的元素,并定义一些方法来实现堆的常见操作,如插入元素、删除堆顶元素等。下面是一个简单的实现示例:
class MaxHeap {
constructor() {
this.heap = [];
}
// 插入元素
insert(value) {
this.heap.push(value);
this.bubbleUp(this.heap.length - 1);
}
// 删除堆顶元素
extractMax() {
const max = this.heap[0];
const end = this.heap.pop();
if (this.heap.length > 0) {
this.heap[0] = end;
this.sinkDown(0);
}
return max;
}
// 上浮操作
bubbleUp(index) {
const element = this.heap[index];
while (index > 0) {
const parentIndex = Math.floor((index - 1) / 2);
const parent = this.heap[parentIndex];
if (element <= parent) {
break;
}
this.heap[parentIndex] = element;
this.heap[index] = parent;
index = parentIndex;
}
}
// 下沉操作
sinkDown(index) {
const left = 2 * index + 1;
const right = 2 * index + 2;
let largest = index;
if (left < this.heap.length && this.heap[left] > this.heap[largest]) {
largest = left;
}
if (right < this.heap.length && this.heap[right] > this.heap[largest]) {
largest = right;
}
if (largest !== index) {
const temp = this.heap[index];
this.heap[index] = this.heap[largest];
this.heap[largest] = temp;
this.sinkDown(largest);
}
}
}
在上述代码中,MaxHeap 类定义了一个数组 heap 来保存堆的元素,同时实现了 insert、extractMax、bubbleUp 和 sinkDown 方法,分别用于插入元素、删除堆顶元素、上浮操作和下沉操作。
在 bubbleUp 方法中,使用循环来不断将新插入的元素上浮,直到满足堆的条件;sinkDown 方法中,首先找出当前节点的左子节点和右子节点,然后将当前节点与两个子节点中的最大值进行比较,如果当前节点的值小于最大值,则交换两个节点的值,并递归进行下沉操作,直到满足堆的条件。
上面定义类的使用方式如下:
const maxHeap = new MaxHeap();
maxHeap.insert(26);
maxHeap.insert(103);
maxHeap.insert(721);
maxHeap.insert(911);
maxHeap.insert(202);
console.log(maxHeap.heap); // [ 911, 721, 103, 26, 202 ]
const max = maxHeap.extractMax();
console.log(max); // 911
console.log(maxHeap.heap); // [ 721, 202, 103, 26 ]
上面代码首先创建了一个最大堆 maxHeap,插入了一些元素。然后,调用 extractMax 方法来删除堆顶元素,得到最大值并打印。最后,打印修改后的堆结构,可以看到堆顶的元素已经被删除并且堆的结构已经满足最大堆的条件。
在 Web 开发中,文件下载功能是一个非常常见的功能。在本文中,将介绍在 JavaScript 中如何实现下载文件。
使用 location.href
当需要打开新页面时,在 JavaScript 中可以使用 location.href 。在某些情况下,可以用它来下载文件,当然这里的下载实际上依赖于服务器设置。因为当浏览器检测到 url 的响应是不支持的类型时,它将下载文件而不是直接预览,通常是设置 content-type。
使用 标签的下载属性
HTML5 中的 download 属性用于用户点击超链接时下载文件。
此属性指示浏览器下载 URL 而不是导航到它,因此将提示用户将其保存为本地文件。如果属性有一个值,那么此值将在下载保存过程中作为预填充的文件名(如果用户需要,仍然可以更改文件名)。此属性对允许的值没有限制,但是 / 和 \ 会被转换为下划线。大多数文件系统限制了文件名中的标点符号,因此,浏览器将相应地调整建议的文件名。
- 此属性仅适用于同源 URL。
- 尽管 HTTP URL 需要位于同一源中,但是可以使用
blob:URL和data:URL,以方便用户下载使用 JavaScript 生成的内容(例如使用在线绘图 Web 应用程序创建的照片)。 - 如果 HTTP 头中的
Content-Disposition属性赋予了一个不同于此属性的文件名,HTTP 头属性优先于此属性。 - 如果 HTTP 头属性
Content-Disposition被设置为inline(即Content-Disposition='inline'),那么Firefox优先考虑 HTTP 头Content-Dispositiondownload属性。
使用 API 下载文件
使用 blob: ,在 JavaScript 中实现下载的常用方式。通过 API 获取URL数据并将其转换为 blob。对于受同源URL限制的文件,可以使用 fetch,因为 fetch 支持来自跨源的请求数据。
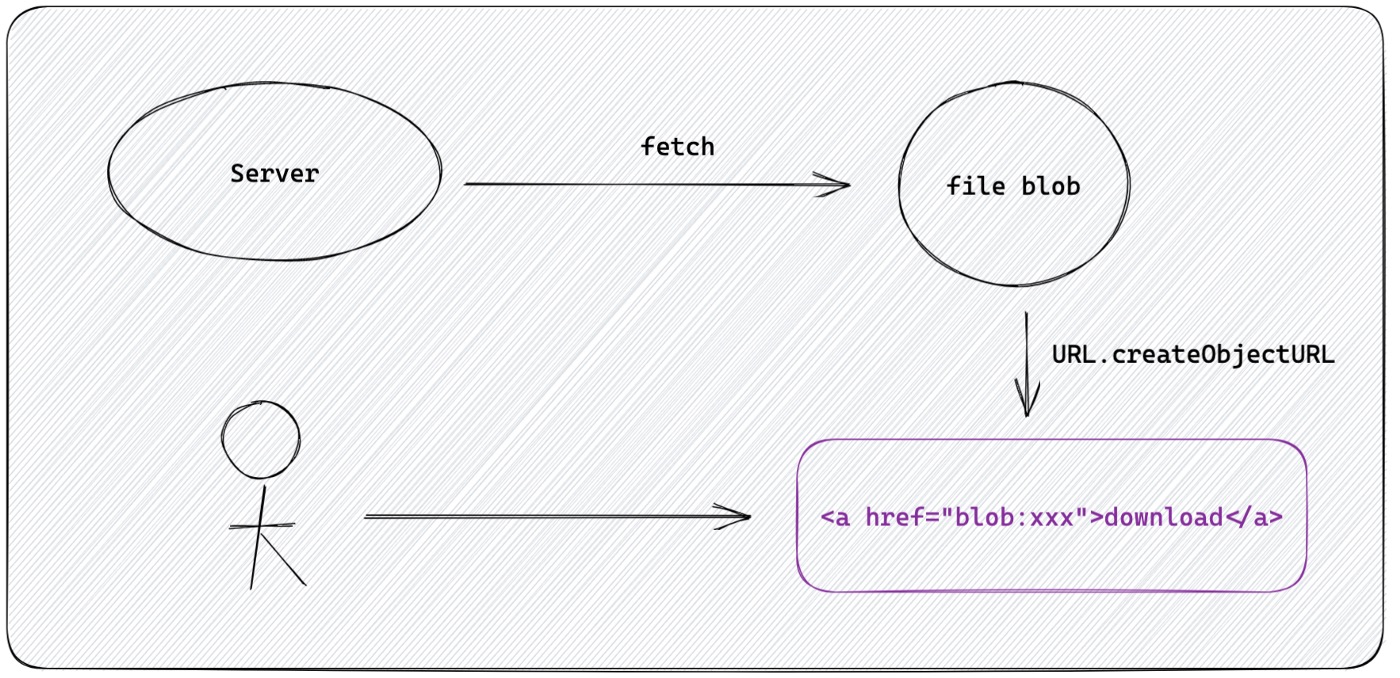
可以使用下面的函数来下载文件:
function downloadFile(url, fileName) {
fetch(url, {
method: "get",
mode: "no-cors",
referrerPolicy: "no-referrer",
})
.then((res) => res.blob())
.then((res) => {
const aElement = document.createElement("a");
aElement.setAttribute("download", fileName);
const href = URL.createObjectURL(res);
aElement.href = href;
aElement.setAttribute("target", "_blank");
aElement.click();
URL.revokeObjectURL(href);
});
}
Django 是一款使用 Python 编程语言开发的 Web 应用程序框架,其内置了一些强大的数据库操作功能,包括增删改查等操作。Django 使用的是 ORM(对象关系映射)技术,可以通过 Python 对象操作数据库,而不需要直接编写 SQL 语句,简化了开发人员的工作。它遵循了 MVC(Model-View-Controller)的设计模式,并采用了 MTV(Model-Template-View)的设计思想,是一款功能强大、易于上手、高度可定制的 Web 应用程序框架。
在使用 Django 进行数据库增删改查操作时,其效率取决于多个因素,包括但不限于以下几个方面:
- 数据库类型和配置:不同的数据库类型和配置对性能有着重要影响。Django 支持多种数据库类型,包括 MySQL、PostgreSQL、SQLite 等,每种数据库类型都有不同的性能特点和优化方式。
- 数据库模型设计:良好的数据库模型设计可以提高数据库操作的效率。合理的模型设计可以使得查询操作更加高效,同时减少数据冗余和数据不一致的问题。
- 数据量和数据结构:数据量和数据结构对数据库操作效率有重要影响。在数据量较大的情况下,查询操作可能会变得缓慢,需要进行分页、缓存等优化操作。
- 硬件和网络环境:硬件配置和网络环境也会对数据库操作效率有重要影响。如果硬件配置较低或网络延迟较高,数据库操作的效率也会相应降低。
总的来说,Django 提供了一些优秀的数据库操作功能,可以帮助开发人员快速地进行数据库增删改查等操作。但是,其效率还是取决于多个因素,需要在具体情况下进行评估和优化。