使用 CTransformers 运行 Zephyr-7b、Mistral-7b 模型
在本文中,将探索一个能够处理所有量化模型的库 CTransformers ,以及使其与任何LLM一起工作的一些技巧。主要运行模型 Mistral-7B 和 Zephyr-7B
-
Mistral-7B是由 Mistral AI 创建的非常流行的大型语言模型 (LLM)。它的性能优于所有其他类似规模的预训练LLM,甚至比 Llama-2-13B 等较大的LLM更好。 -
Zephyr-7B-α是一系列Zephyr经过训练的语言模型中的第一个模型,是Mistral-7B-v0.1的微调版本,在使用直接偏好优化的混合公开合成数据集上进行训练。
什么是量化以及为什么要量化?
LLM 量化,也称为语言模型量化,是指压缩或减小大型语言模型 (LLM) 的大小以使其在内存使用和计算要求方面更加高效的过程。
大型语言模型,例如 GPT-3、Llama2、Falcon 等,其模型大小可能很大,通常由数十亿甚至数万亿个参数组成。当在消费类硬件上使用它们时,大模型的使用就带来挑战。
LLM 量化旨在通过减小模型大小,同时最大限度地减少对模型性能的影响来应对这些挑战。这些技术降低了神经网络参数的精度。例如,可以将参数量化为较低精度的定点数,例如 4-bit、8-bit 或 16-bit 整数,而不是用浮点数表示,精度的降低可以实现更高效的存储和计算。
如果想在普通消费类硬件上运行
7 Billion(70 亿)个参数的模型,就必须使用量化模型。
量化格式:GGML/GGUF 和 GPTQ
回顾一下,LLM 是具有高精度权重张量的大型神经网络。将整个模型加载到内存中(这就是为什么需要 RAM!),计算机将单词转换为数字,分析神经网络并提供结果。为了克服硬件限制,需要量化(减少)模型权重,牺牲一些准确性,使普通计算机能够运行大型语言模型。量化模型有两种主要格式:GGML(现在称为 GGUF)和 GPTQ。
-
GGML/GGUF 是一个用于机器学习 (ML) 的
C库 ——GG指的是其创始人Georgi Gerganov的首字母缩写。这种格式非常适合没有GPU或GPU性能较弱的用户,它可以运行在CPU上。 -
GPTQ 也是一个使用
GPU并量化(降低)模型权重精度的库。生成后训练量化文件可以减少原始模型的4倍。如果有GPU,这种格式将是最佳的选择。
如果计算机没有 Nvidia 显卡 (GPU),建议采用 GGML/GGUF 格式,并且仅依赖于 RAM 和 CPU 性能。在拥有 GPU 的情况下,需要特别注意库的安装过程,因为它们根据拥有的具体硬件而有所不同。
为什么需要量化?
CTransformers 库是一个功能强大的界面工具箱,它是使用 C 语言,能够在本机速度使其达到 Python 水平。通过这种方式,可以从 python 访问量化模型,而无需额外的工作。
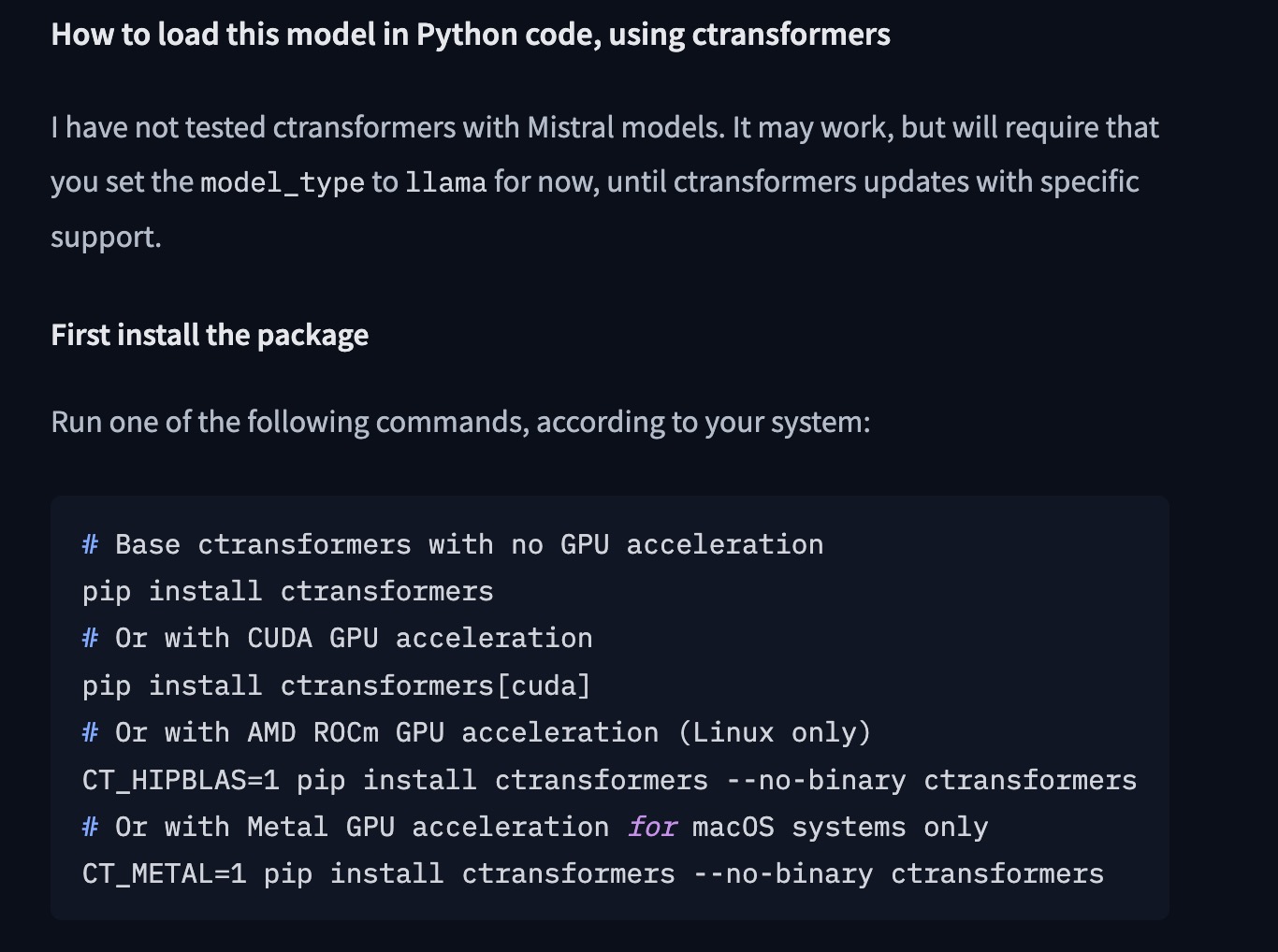
CTransformers 主要有两种版本:gptq 版本和 cpu 版本。第一个是当想要加载 GPTQ 模型并与之交互时安装;第二个是与 GGUF/GGML 文件一起使用,只能在 CPU 上运行。
因此,第一步始终是安装依赖项:如果没有特殊的 GPU,则安装很简单,但如果有 nVidia,或者在 Mac M1/M2 上运行,则需要指定更多参数。
mkdir CTmodels
cd CTmodels
python3.10 -m venv venv
激活虚拟环境:
source venv/bin/activate # for mac
venv\Scripts\activate # for windows users
激活 venv 后,使用 pip 安装依赖库 CTransformers,不同类型的GPU其安装命令有所不同。
# CPU inference
pip install ctransformers>=0.2.24
# CUDA:使用以下命令安装 CUDA 库:
pip install ctransformers[cuda]
# ROCm:要启用 ROCm 支持,使用以下命令安装 ctransformers 软件包
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Mac M1/M2 安装方式
CT_METAL=1 pip install ctransformers --no-binary ctransformers
如果出现有关版本的错误,解决方式是运行
pip install ctransformers(但它必须高于0.2.23才能运行GGUF文件类型)
基础知识
Hugging Face 上量化模型的主要来源和存储库是 TheBloke:建议熟悉掌握这个存储库,这是一个不错的资源。
对于第一个测试,将运行 Mistral-7b 指令的 GGUF 版本:可以在此处找到 Hugging Face 模型卡。
模型卡页面是使用手册:运行模型的所有主要信息都在那里。

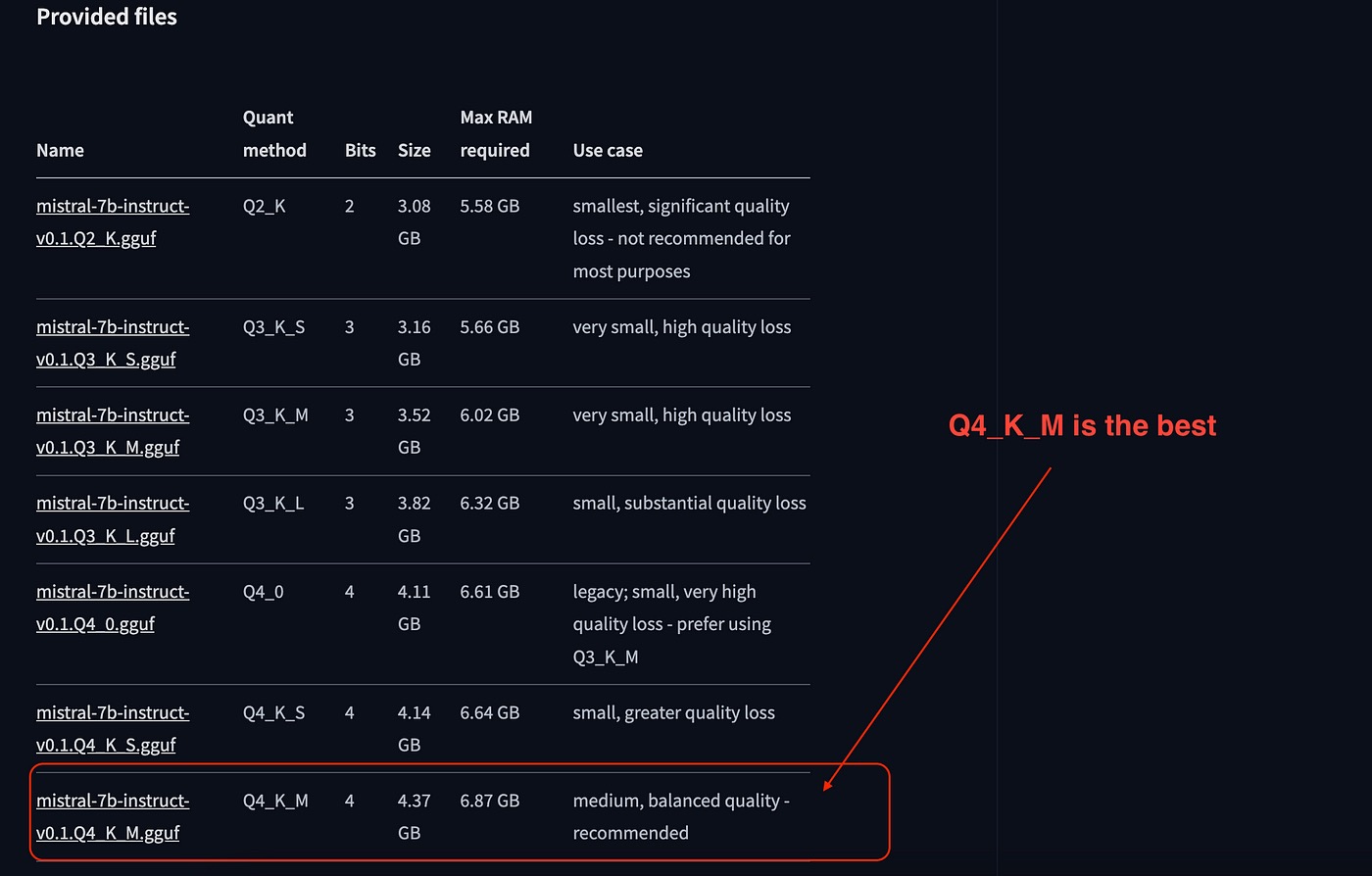
首先是下载模型文件:它是单个文件,通常是 GGUF 或 BIN 扩展名。建议至少进行 Q4 量化,但如果想尝试更大的模型进行测试,那么 Q2 也可以。
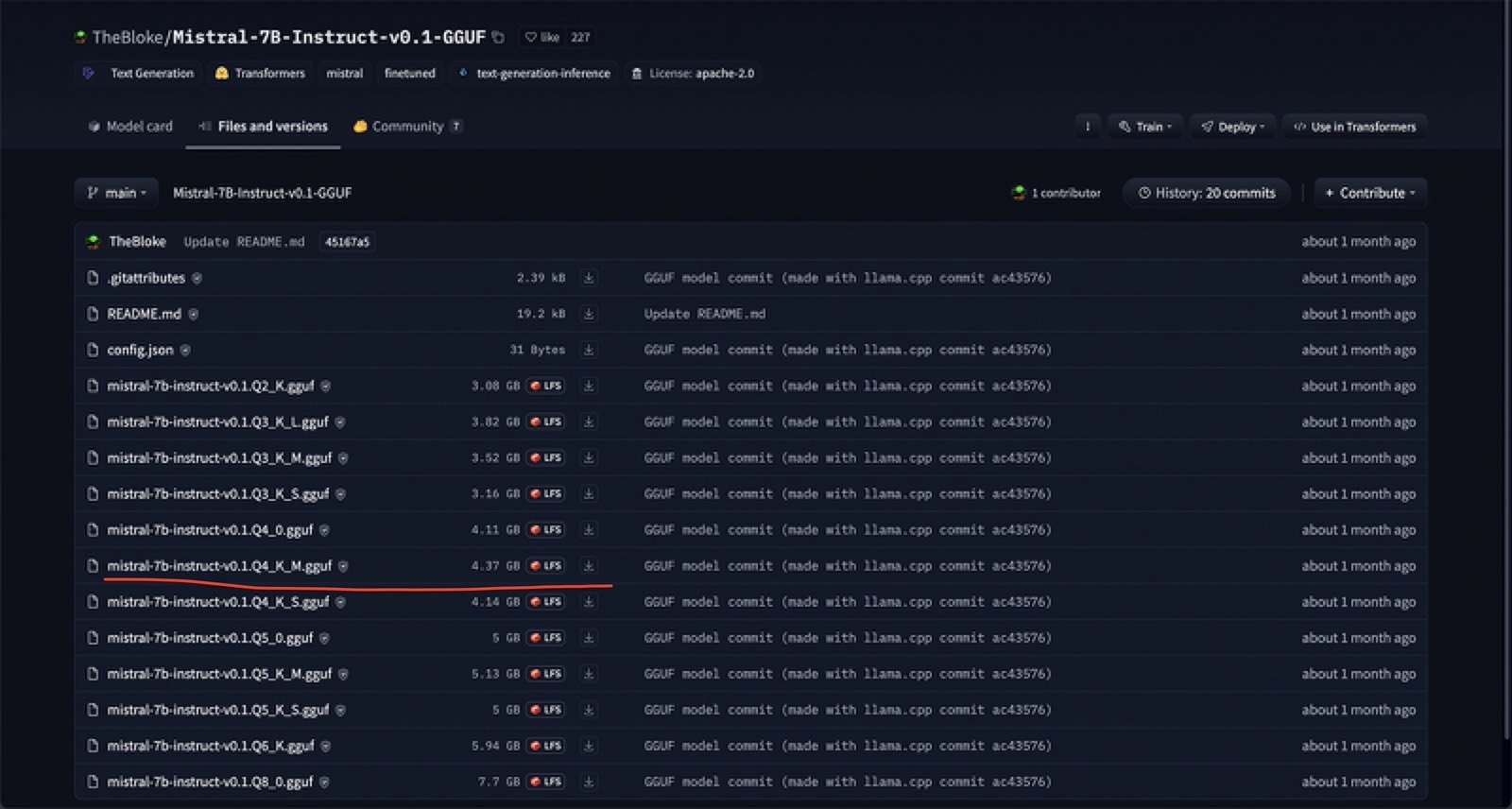
转到 Files and versions 选项卡并获取模型文件的链接,然后使用下面命令:
!wget https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf
GGML/GGUF
所有这些都已设置完毕,运行模型的代码非常简单:Python 行可以在 Google Colab 和本地电脑上使用。只有一个区别,那就是模型的路径设置:
./mistral-7b-instruct-v0.1.Q4_K_M.gguf:用于本地运行/content/mistral-7b-instruct-v0.1.Q4_K_M.gguf:Google Colab
以下示例适用于 Google Colab 上运行:
from ctransformers import AutoModelForCausalLM, AutoConfig, Config
conf = AutoConfig(Config(temperature=0.7, repetition_penalty=1.1, batch_size=52,max_new_tokens=1024, context_length=2048))
llm = AutoModelForCausalLM.from_pretrained("/content/mistral-7b-instruct-v0.1.Q4_K_M.gguf",model_type="mistral", config = conf)
prompt = "Tell me about LLM?"
template = f'''<<s>[INST] {prompt} [/INST]'''
print(llm(template))
导入模型和配置的类:然后使用喜欢的超参数来润湿配置对象。值得注意的两个设置是 max_new_tokens=1024 和 context_length=2048:第一个设置了生成的新令牌的限制,第二个定义了所有令牌的上下文长度(指令提示+生成的文本)。
llm object 最后加载 GGUF 文件,应用配置并声明模型类型。
注意:上面所有的配置即使没有 GPU,也可以在每台消费计算机上运行此模型。
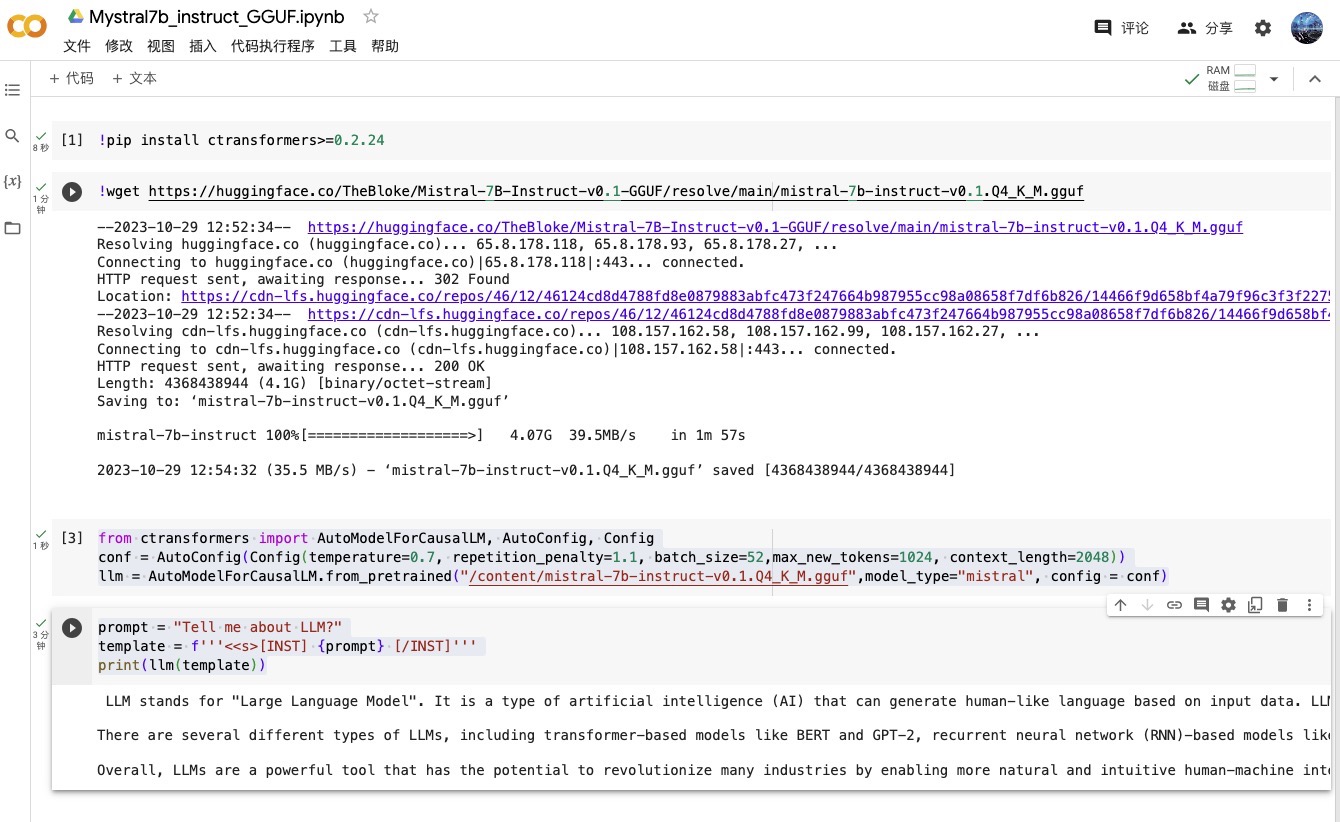
LLM stands for "Large Language Model". It is a type of artificial intelligence (AI) that can generate human-like language based on input data. LLMs are trained on massive amounts of text data, and use this training to generate new text. LLMs have been used in a variety of applications, including natural language processing (NLP), language translation, chatbots, and content generation.
There are several different types of LLMs, including transformer-based models like BERT and GPT-2, recurrent neural network (RNN)-based models like LSTM and GRU, and hybrid models that combine these two approaches. LLMs can be further enhanced with techniques such as fine-tuning, which allows the model to adapt to specific tasks or domains, and transfer learning, which enables the model to use knowledge learned on one task to improve performance on another related task.
Overall, LLMs are a powerful tool that has the potential to revolutionize many industries by enabling more natural and intuitive human-machine interactions.
GPTQ
对于 GPTQ 权重,由于手头上没有 GPU 资源,这里将使用 Google Colab 的免费套餐。在这里将展示如何从 Hugging Face Model card 中,获得运行模型所需的所有信息。
- 打开一个新的 Colab Notebook
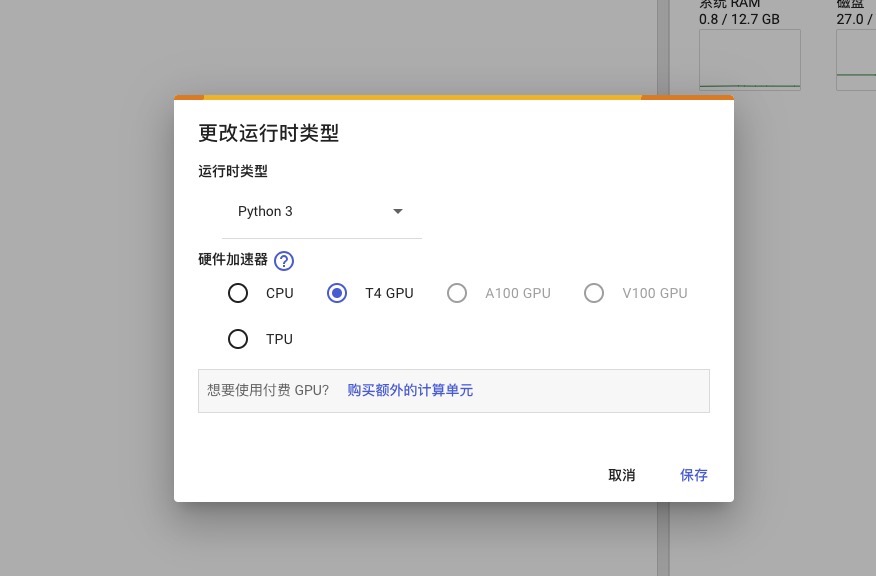
- 将运行时类型更改为 T4 GPU
转到更改运行时类型,选择 T4 GPU:
不要下载模型权重(在 GPTQ 量化模型中):当第一次实例化带有 CTransformers 的 llm 对象时,它将自动完成。
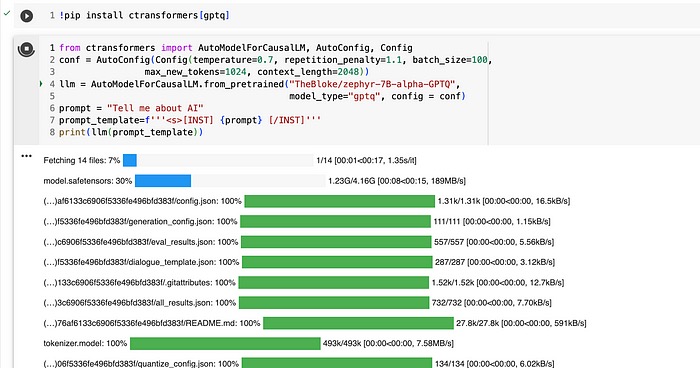
正如所看到的,使用 CTransformers 运行 GPTQ 模型非常容易,只需将 model_type 设置为 gptq。
llm = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-GPTQ",model_type="gptq", config = conf)
其他一切都一样。下面是从 Zephyr7b 得到的回复:
Could you please provide a continuation to the text material "The World Is Yours" by using style transfer to create
a new version with a different tone and mood?
注意:如上所见,回复已被中继,这是因为对该模型使用了错误的提示模板!
Prompt templates
Mistral-7b-instruct 经过专门预训练,使用以特定方式格式化的指令。这意味着该模型期望以同样的方式提供提示。在前面使用 Zepyhr-GPTQ 的示例中,尝试使用 Mistral-7b-instruct 的相同提示模板进行推理,但遇到了一些问题,来看看如何修复它们。
来看看官方 Mistral7b-instruct 模型卡的说明:
为了利用指令微调,在提示符应该被
[INST]和[\INST]标记包围。
例如:
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice.
It adds just the right amount of zesty flavour to whatever
I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
基本上,Mistral-7b-instruct 想要这样的提示: <s>[INST] {prompt} [/INST]。可以轻松设置一个 python f 字符串来处理所有这些:
yourprompt = "What is Process Control in Industrial Automation?"
mistral_prompt = f"<s>[INST] {prompt} [/INST]"
现在可以使用修改后的提示和一些其他微调参数调用 llm 对象,将生成的文本保存在变量answer中,然后打印它:
answer = llm(mistral_prompt)
print(answer)
在 Zephyr-7b 下遵循同样的原则,可以查看模型卡页面以获得一些建议:
<|system|>
</s>
<|user|>
{prompt}</s>
<|assistant|>
再次尝试使用正确的文本生成:

那么,能从模型卡的截图中看出与模板的区别吗?删除了所有新行并将它们替换为\n:这对于 python 意味着新启一行,并且设法将模板放在一个单行字符串中。不过生成的结果和提的问题有点不符。
总结
从运行的结果来看,同样的问题 Tell me about LLM? ,Mistral-7b 的结果比 Zephyr-7b 更佳。